


Build generating applications based on scaled cloth on AWS using Amazon EK with Amazon Bedrock
Artificial intelligence (AI) generating applications are usually constructed using a technique called the added generation of relapse (RAG) that provides Foundation Models (FMS) access to additional data they did not have during training. These data are used to enrich the generating promotion of it to provide more specific and accurate context answers without continuously retraining FM, also improving transparency and minimizing hallucinations.
In this post, we demonstrate a solution using the Amazon Elastic Kubbernetes (EC) service with Amazon Bedrock to build scaled solutions and containers for your AWS generating applications while bringing your non -structured user file data to Amazon Bedrock in a direct, fast and secure way.
The Amazon EG provides an escalating, safe and cost -effective environment for building LCKA applications with Amazon Bedrock and also enables efficient placement and monitoring of work driven by it while using Bedrock FMS for conclusions. It increases the performance with optimized calculation cases, GPU automatic workloads while reducing costs through Amazon EC2 and AWS Fargate instances and provides enterprise degree through local AWS mechanisms as Amazon VPC Networking and AWS IAM.
Our solution uses Amazon S3 as the source of non -structured data and populates an Amazon Opensearch -free vector base through the use of Amazon Bedrock Knowledge with existing user files and folders. This enables a Rag scenario with the Amazon Bedrock by enriching a quick generating of it using Amazon Bedrock APIs with your company’s specific data obtained from the Opensearch serverless vector database.
Settlement
The solution uses node groups managed by Amazon EC to automate management of provision and nodes life cycle (Amazon EC2 instances) for the Amazon Cubens cluster. Nodedo Nodes Managed in the grouping is provided as part of an Amazon EC2 vehicle scaling group managed for you by ex.
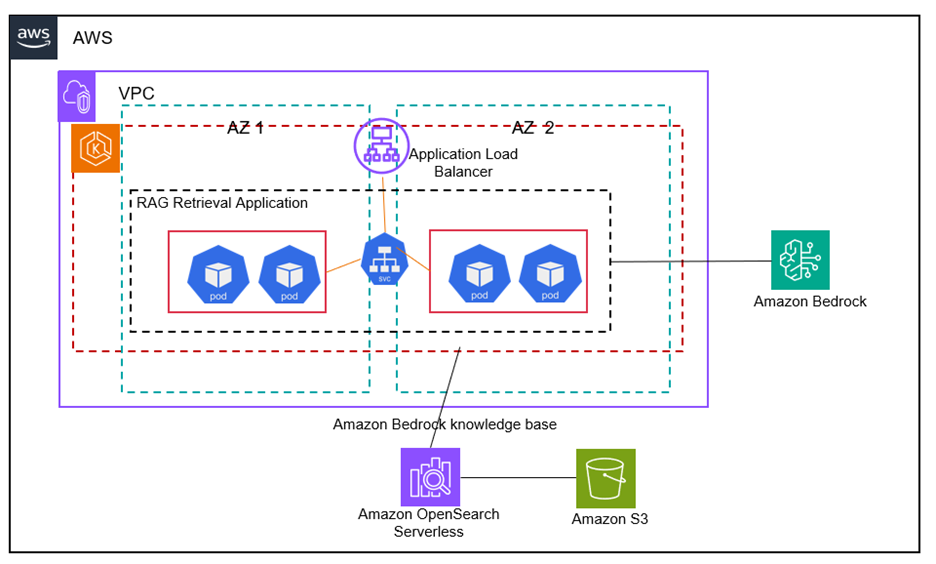
The EC batch consists of a placement of cubenetes that runs into two areas of high availability availability, where each node in the placement expects multiple copies of an image of the bed cloth container recorded and drawn from the elastic register of the Amazon (ECR). This configuration ensures that resources are used efficiently, scaling up or down the request. Horizontal Pod Autoscaler (HPA) is set to further scale the number of pods in our placement based on their use of CPU.
Application container for Rag reaction uses Baildrock Bases API and Anthropic’s Claude Bases 3.5 Sonnet LLM organized in bedrock to implement a Rag work flow. The solution provides the final user with an escalating final point to access the Rag’s workflow using a cubenetes service which is forward from an Amazon app load balance sheet provided through an MGress Ex control.
A container for applying the orchestrated cloth with the AMAZON’s bed enables a quick generation of it obtained from the last point of Alb with the data obtained from a server index that is synchronized through bedding from the specific data of your company loaded in the Amazon S3.
The following diagram of architecture illustrates the different ingredients of our solution:

PRECONDITIONS
Complete the following prerequisites:
- Provide access to the model on the Amazon bed. In this solution, we use anthropic Claude 3.5 sonnets on the Amazon bed.
- Install the AWS (AWS CLI) command line interface.
- Install Docker.
- Install Kubectl.
- Install terraform.
Set up the solution
The solution is available to be downloaded in Repo Github. Cloning of warehouses and using terraform model will provide ingredients with their required configuration:
- Clonone GIT:
- from
terraformFile, set the solution using terraorm:
Configure ek
- Configure a secret to ECR register:
- Navigate in
kubernetes/ingressfolder:- Make sure
AWS_Regionvariablebedrockragconfigmap.yamlThe file shows in your AWS region. - Replace the hunger image in row 20 of
bedrockragdeployment.yamlfile with the hunger image ofbedrockragimage from your ECR warehouse.
- Make sure
- Providing placement, service and entry to EM:
Create a basis of knowledge and upload data
To create a basis of knowledge and to load data, follow the following steps:
- Create a S3 bucket and upload your data to the bucket. In our blog post, we uploaded these two files, Amazon Bedrock and Amazon FSX guide for Ontap user guide in our S3 bucket.
- Create a knowledge base at Amazon Bedrock. Follow the steps here to create a basis of knowledge. Accept all defaults including the use of Quickly create a new vector store option In Step 7 of the guidelines that create a collection of Amazon -free vector search, as your knowledge basis.
- In step 5C of the instructions to create a knowledge basis, provide S3 hunger of the object containing files for data source for knowledge base
- Once the knowledge basis is provided, get The id of the basis of knowledge From the keyboard of knowledge basis for the knowledge basis for your newly created knowledge basis.
Question using the app upload balancer
You can request the model they use directly on the anterior edge API provided by AWS ALB provided by the entry controller in the cubenetes (EG). Navigate on the AWS Alb keyboard and get Name For your ALB to use as your api:
cleaning
To avoid repeated fees, clean your account after you have tried the solution:
- From the terraform file, delete the terraorm model for the solution:
terraform apply --destroy - Delete the knowledge base of the Amazon Bedrock. From the Amazon Bedrock keyboard, select the basis of the knowledge you have created in this solution, select excreteand follow the steps to delete the basis of knowledge.
cONcluSiON
In this post, we demonstrated a solution used by Amazon ex with Amazon Bedrock and offers you a framework to build your container generating applications, automated, scaled and highly available Rag based on AWS. Using the knowledge basics of Amazon S3 and Amazon Bedrock, our solution automates the data behavior of your User Structured User file in Amazon Bedrock within the contained framework. You can use the demonstrated approach to this solution to automate and container your work loads directed by it while using the Amazon Bedrock FMS for Conclusion in integrated placement, scaling and availability from a cubene -based container placement.
For more information on how to start construction with Amazon Bedrock and EK for Rag scenarios, refer to the following resources:
About
 Kanishk Mahajan It is the director, the AWS architecture solutions. It directs the cloud transformation and the architecture of the AWS clients and partners. Kanishk specializes in containers, cloud operations, migrations and modernizations, AI/ML, resistance and safety and compliance. He is a member of the technical community of the field (TFC) in each of those fields in AWS.
Kanishk Mahajan It is the director, the AWS architecture solutions. It directs the cloud transformation and the architecture of the AWS clients and partners. Kanishk specializes in containers, cloud operations, migrations and modernizations, AI/ML, resistance and safety and compliance. He is a member of the technical community of the field (TFC) in each of those fields in AWS.
 Sandeep Batch He is a senior security architect at Amazon Web Services, with extensive experience in software engineering, solutions architecture and online security. Passionate after building business results with technological innovation, Sandeep guides customers through their journey to the Cloud, helping them design and implement cloud architecture safe, scaled, flexible and resilient.
Sandeep Batch He is a senior security architect at Amazon Web Services, with extensive experience in software engineering, solutions architecture and online security. Passionate after building business results with technological innovation, Sandeep guides customers through their journey to the Cloud, helping them design and implement cloud architecture safe, scaled, flexible and resilient.





Leave feedback about this