



Python ml tupelines with Scikit-Meni: Guide to a beginner
If you’ve ever built a Python machine learning model, you know how quickly things can become messy. Among the cleaning of your data, transforming features and training your model, it is easy to lose track of what happens when the mistakes can crawl. This is where the Scikit-Learn pipes enter.
Pipelines act as a list to do for the course of your machinery learning work, helping you organize any forecast processing-in a clear, repetitive process. They not only make your code easier to read and maintain, but also help prevent common mistakes as data leakage.
In this post, I will explain what pipelines are, how to build one from the first and how they can help run your workflow. Whether just starting or looking to clean your existing code, this guide will help you build smarter, faster machinery learning projects with confidence.
I will work at Sas Viya Workbench which allows me to rotate without problems with all packages, libraries and calculating sources I need.
What are the piping learned from the skikit?
Imagine you are following a recipe to make a chocolate cake – you would not accidentally remove the steps and try to make them all right away; Instead, you follow every step in order to create the perfect cake. Similarly, a machine learning work requires tracking each step sequentially: data cleaning, transforming it, training the model and then making predictions.
Pipelines learned by SCIKit organize this workflow in a single, effective process that keeps your code clean and manageable. They also simplify the award of hyperparameter, cross certification and pattern comparison.
Putting your environment
Now that you understand the basics of why we use the pipes learned from the Scikit, let’s set your environment! Sas Viya Workbench already has all the packages I need, but if you don’t already, go ahead and install numpy, scikit-learning and pandas using installation Pip.

Building your first pipeline
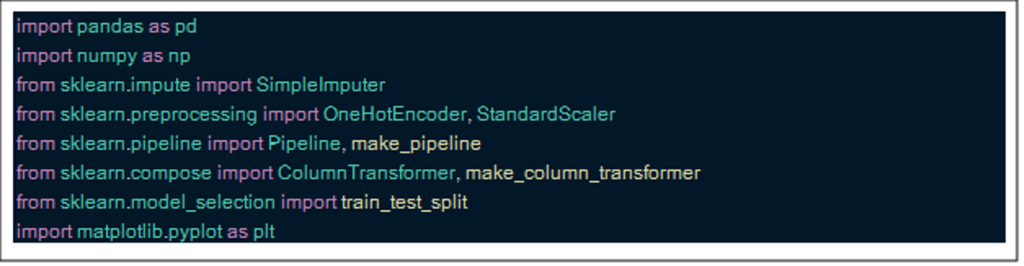
Step 1: Import all packets for the pipeline
The first thing I always do when starting a new project is to import all parts of a pipeline that I need so everything is in one place.
Step 2: Upload your data
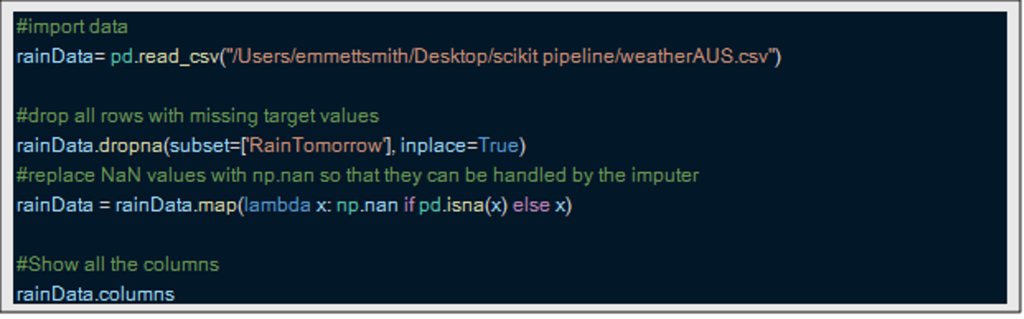
The first step is to upload your data. For this example, I am using a database from Kaggle that predicts the rain in Australia based on last day’s weather conditions. Data data contain 20 variables that can help predict whether it will rain the next day. While I will not immerse deep in data data here, it is important in any data science project to explore data to fully understand them, select the best processing methods and select the best modeling methodologies to try.
I also did some first processing -processing by removing each line without a target value to predict and transform all values that are missing in nann nan to simplify the first steps.
Step 3: Creating a column transformer
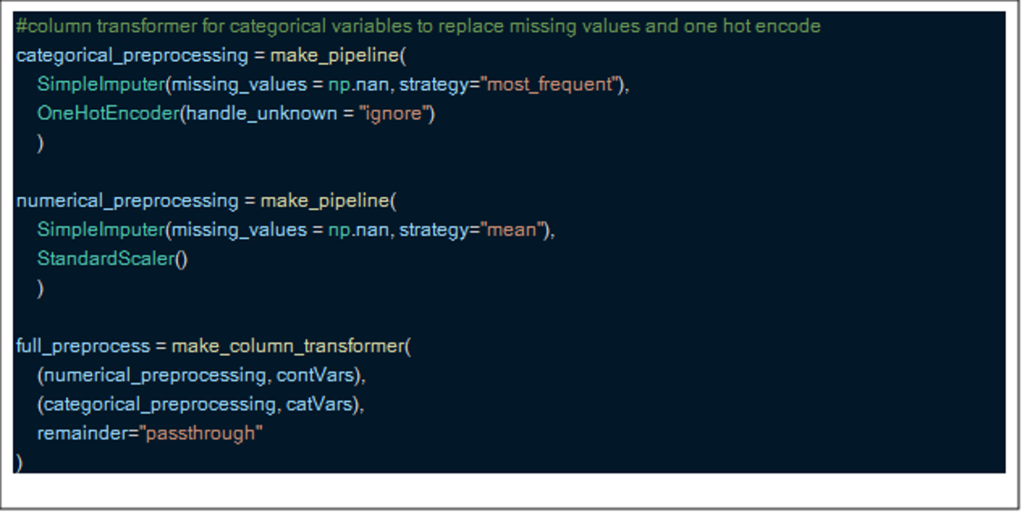
You can wonder what a column transformer is and why it is necessary. Simply put, most data contain categorical and numerical columns, which require different processing steps. A column transformer allows you to apply different processing steps for each type of data.
In this case, I imposed the numerical data lost with the average and applied a standard scales. For categorical data, I imposed using the most frequent response and finally made a hot coding. As you can see, each processing feature has its own pipeline which is useful, as the column transformer can execute these in parallel to speed up before -processing.
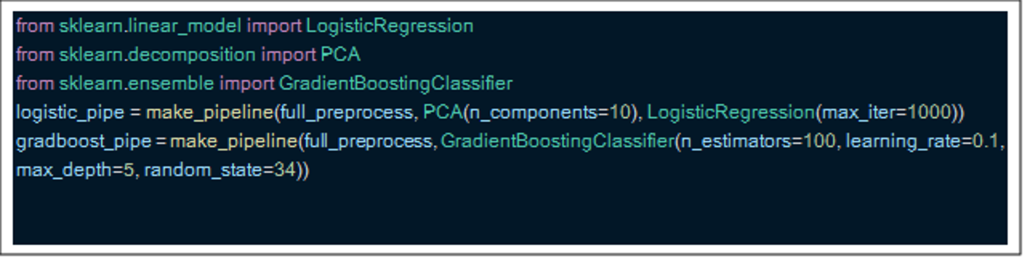
Step 4: Add patterns to create full pipeline
I have chosen to show a pipeline of a key component analysis model (PCA) combined with a logistical regression pattern, and a second gradient stimulus pipeline. The only difference I needed to change was the name of the last step, and both pipes work the same.
Here is a last diagram of the logistical regression pipeline, where we can see the first two pipelines -processing in our column be transformed before we enter our PCA and logistical regression models.
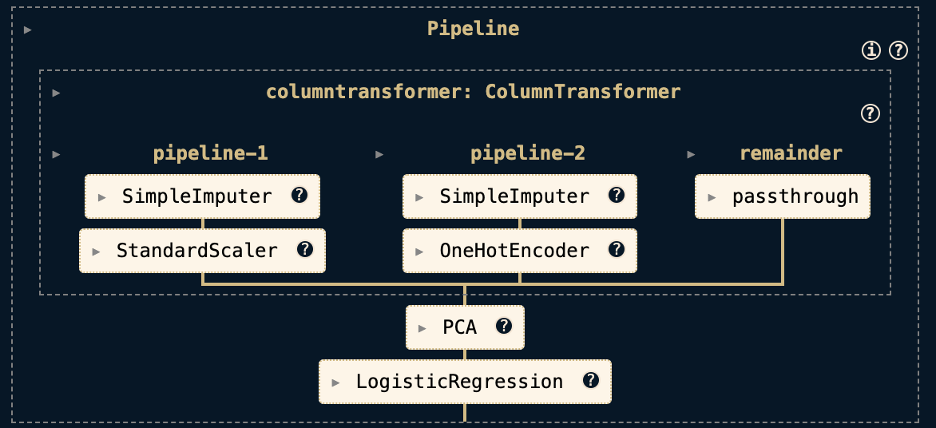
Step 5: Adapt and tick the patterns
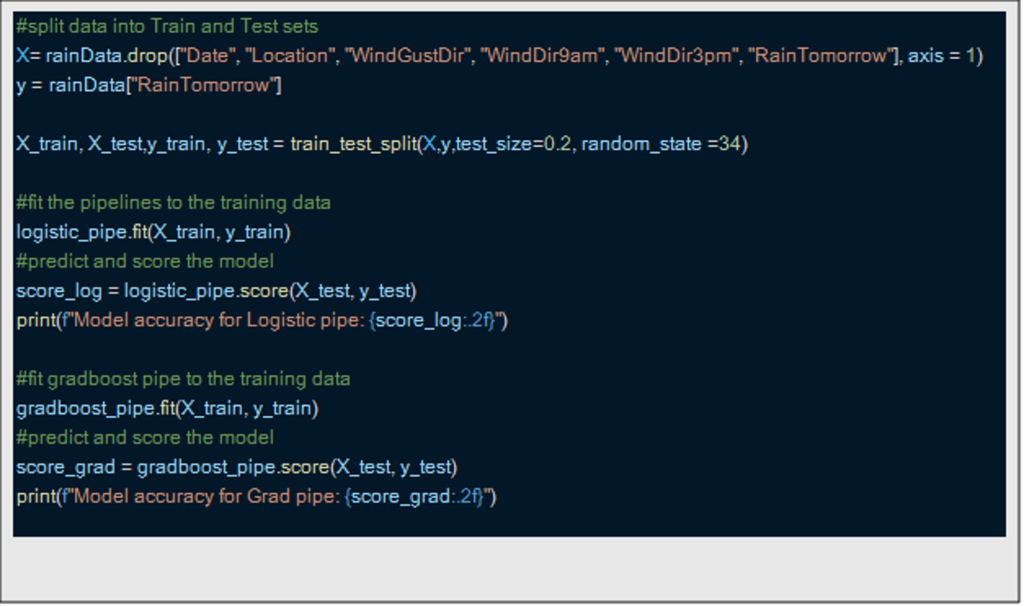
Finally, I divided the data into training and trial groups before fitting and appreciating both models. The gradient growth model exceeded the logistical regression with 2 percentage points (85% VS 83%), but it took 41 seconds to adapt and marked compared to only 1.6 seconds for logistical regression – an important consideration for the use of large data.
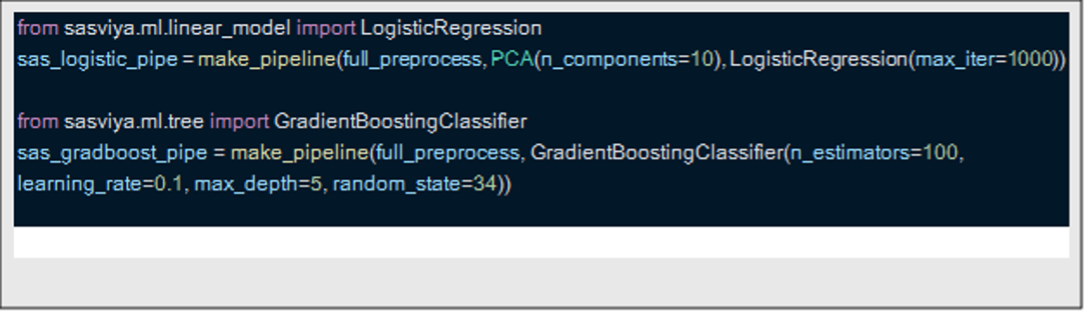
To speed up the pipelines, namely the gradient growth model, I also tried the same pipes, but simply changed the import statement and created special pipeline objects. I am displaying only the code lines that I have changed as everything else is the same. This simple change reduced the gradient growth time to 2.5 seconds and logistical regression in just 1 second, demonstrating significant performance improvements offered by Sas Viya workbench.
Congratulations! Now you have created your first pipeline!
Why do pipelines matter
Now that you have created a pipeline, you may wonder why use one instead of writing the step -by -step code. Here are four reasons that can help the answer that:
1. Avoiding data leakage
Data flow occurs when outside information of training data is used to create the model, leading to extremely optimistic performance estimates. Pipelines help prevent this by ensuring that all processing steps are applied only to training data during mounting, and then applied continuously to the test data during the forecast.
2. Keeping the first steps -processing and modeling together
By catching the processing and modeling openings in a single object, the pipes make your code more modular and easier to manage. This structure reduces the risk of applying opposition transformations and simplifies debugging and cooperation.
3. Easier search of the intersection and network rating
Pipelines integrate smoothly with the tools of selecting the Scikit-Learn model. You can allocate the hyperparations throughout the pipeline, including processing steps, using tools like Gridsearchcv and Cross_val_score. This ensures that your evaluation measurements reflect the true performance of the entire workflow.
4. Using JOBLIB for model perseverance
Once your pipeline has been trained, you can save the entire facility – including pre -processing and model steps – for subsequent use. This makes it easy to place your model, archive it or share it with others without having to re-direct the whole training process.
Ordinary traps and how to avoid them
Even with pipelines, there are some common mistakes to see:
Forgetting to include processing in the pipeline
The processing steps carried out outside the pipeline can lead to inconsistency between training and forecasting. Always include all transformations inside the pipeline to ensure durability and reproducibility.
Data leak from the test group
Be careful not to adapt any transformation throughout the database before dividing into training and evidence groups. Pipelines help mitigate this risk by ensuring that transformations are only suitable for training data.
Misuse of Fit_transform VS Transformation
During training, use Fit_transform to learn and apply transformations. During testing or conclusion, use the transformation to apply the same transformations without adjusting. Pipelines handle this difference automatically, but it is important to understand when working outside them.
Final thoughts and next steps
Skik teaching pipes provide a structured, efficient and error resistant way to build machinery learning models. They help you:
- Avoid data flow
- Keep the Clean and Modular Code
- Simplify crucified rating and hyperparameter tuning
- Activate the model’s perseverance with Joblib
As you continue to explore the pipes, consider learning:
- Trait For the combination of multiple feature extraction processes
- Grusearchcv For the tuning of hyperparameters throughout the pipeline
- Custom transformers For the construction of reusable processing components adapted for your data
Pipelines are a fundamental tool in any machinery learning work flow. Start using them early, and you will build patterns that are not only more accurate but also easier to maintain and place. and i find them to be
Pipelines are a fundamental tool in any machinery learning work flow. Start using them early to build models that are not only more accurate but also easier to maintain and set up. I encourage them to try them – you can find them just as useful as I have.





Leave feedback about this