



Benchmarking Top Vision Vision Language Models (VLMS) for picture classification
%20for%20Image%20Classification_%20Performance%20Benchmarks.png?width=1000&height=556&name=Best%20Vision%20Language%20Models%20(VLMs)%20for%20Image%20Classification_%20Performance%20Benchmarks.png)
presentation
In the rapid evolution of artificial intelligence, the ability to accurately interpret and analyze visual data is becoming increasingly important. From autonomous vehicles to medical images, image classification applications are large and influential. However, as the complexity of tasks increases, as well as the need for models that can smoothly integrate numerous modalities, such as vision and language, to achieve a stronger and nuanced meaning.
This is where vision language models (VLM) come into play, offering a powerful approach to learning multimodal by combining image and text inputs to generate significant results. But with so many models available, how can we determine which one performs best for a particular task? This is the problem we aim to address on this blog.
The main purpose of this blog is to define the high vision language patterns in an image classification task using a basic database and compare its performance with our model of general image recognition. Moreover, we will demonstrate how to use the model-standard tool to evaluate these models, providing knowledge of their strengths and weaknesses. In doing so, we hope to shed light on the current state of VLM and guidance practitioners in choosing the most suitable model for their specific needs.
What are the Language Language Models (VLM)
A vision language model (VLM) is a type of multimodal generator that can process both image and text inputs to generate text results. These models are very versatile and can be applied to a variety of tasks, including but not limited to:
- Answer the Question of the Visual Document (QA): answering questions based on visual documents.
- Chapter of Figure: Generation of Descriptive Text for Images.
- Image classification: Identifying and categorizing objects within images.
- Discover: condition of objects within an image.
The architecture of a typical VLM consists of two main ingredients:
- Image feature extractor: This is usually a pre-trained vision model as vision transformer (year) or clip, which derives traits from the input image.
- Text Decoder: This is usually a large linguistic model (LLM) such as Llama or QWEN, which generates text based on the features of extracted
These two ingredients are joined together using a layer of mode melting before they get into the language decipher, which produces the end result of the text.
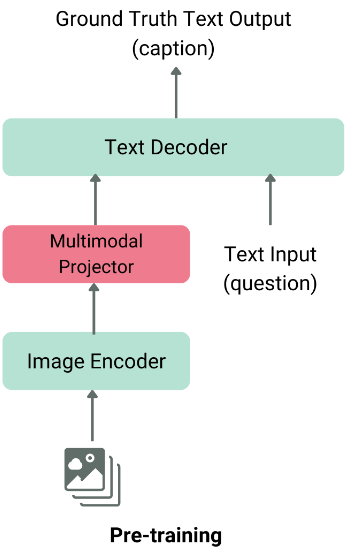
VLM general architecture, image obtained from HF blog.
There are many vision language models available on the Clarifai platform, including GPT-4o, Claude 3.5 Sonnet, Florence-2, Gemini, QWEN2-VL-7B, Llava, and MinicPM-V. Try it here!
Current state of VLMS
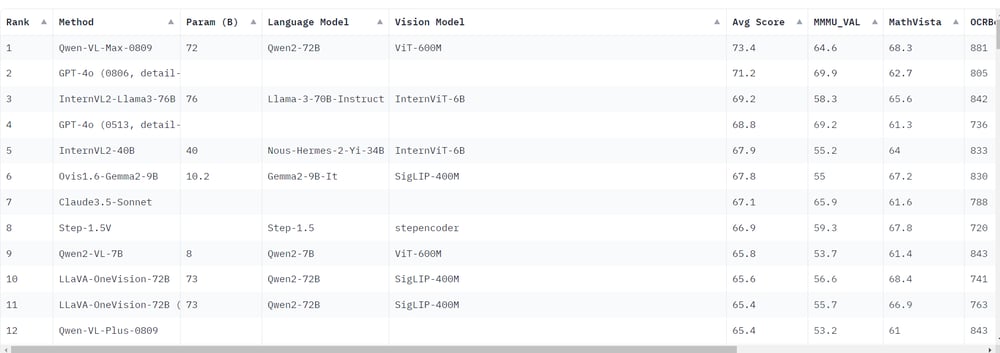
The last rankings indicate that QWEN-VL-MAX-0809 has exceeded further GPT-4o In terms of average standards results. This is significant because the GPT-4o was previously considered the highest multimodal model. Increasing large -sourced -sourced models like QWEN2-VL-7B It suggests that open source models have begun to exceed their closed source counterparts, including GPT-4o. In particular, qwen2-vl-7b, despite its smallest size, achieves results that are close to those of trading models.
Setting the experiment
Equipment
Experiments were performed on the Lambda Labs device with the following specifications:
|
CPU |
RAM (GB) |
GPU |
VRAM (GB) |
|---|---|---|---|
|
AMD EPYC 7J13 64-Core Processor |
216 |
A100 |
40 |
Patterns of interest
We focused on smaller models (less than 20b parameters) and included GPT-4o as a reference. Estimated models include:
|
pattern |
Mmwanness |
|---|---|
|
Instruction qwen/qwen2-vl-7b |
54.1 |
|
OpenBMB/Minicpm-V-2_6 |
49.8 |
|
Meta-lama/llama-3.2-11b-vision-stroke |
50.7 (Cot) |
|
Lava-hf/lava-v1.6-amrinal-7b-hf |
33.4 |
|
Microsoft/Phi-3-Vision-128K-INSTRUCTION |
40.4 |
|
Lava-hf/llama3-Slav-next-8b-hf |
41.7 |
|
Opengvlab/Internvl2-2b |
36.3 |
|
Gpt4o |
69.9 |
Conclusion Strategies
We have used two main conclusion strategies:
- Established Strategy Locked: We have used standard metrics to compare these frames, including:
- The model is equipped with a list of quick class names.
- To avoid the prejudice of the position, the model is asked the same question several times with the names of the interconnected classes.
- The final response is determined by the most common class in the model’s responses.
- Quick example:
“Q: Answer this question in one word: What kind of object is in this photo? Choose one of {class1, class_n. Reply:
“
- Binary -based question strategy:
- The model is required a series of yes/not for each class (excluding background class).
- The process stops after the first ‘yes’ response, with a maximum of (number of classes – 1) questions.
- Quick example:
“Answer the question in a word: yes or no. Is {class} in this photo?“
results
Dataset: Caltech256
Caltech256 data data consists of 30,607 images in 256 classes, plus a clutter in the background. Each class contains between 80 and 827 images, with image size ranging from 80 to 800 pixels. A subset of 21 classes (including background) was randomly selected for evaluation.
|
pattern |
macro avg |
AVG with weight |
ACCURATELY |
GPU (GB) (Infert Series) |
Speed (it/s) |
|---|---|---|---|---|---|
|
GPT4 |
0.93 |
0.93 |
0.94 |
N/a |
2 |
|
Instruction qwen/qwen2-vl-7b |
0.92 |
0.92 |
0.93 |
29 |
3.5 |
|
OpenBMB/Minicpm-V-2_6 |
0.90 |
0.89 |
0.91 |
29 |
2.9 |
|
Lava-hf/lava-v1.6-amrinal-7b-hf |
0.90 |
0.89 |
0.90 |
|
|
|
Lava-hf/llama3-Slav-next-8b-hf |
0.89 |
0.88 |
0.90 |
|
|
|
Meta-lama/llama3.2-11b-vision-stroke |
0.84 |
0.80 |
0.83 |
33 |
1.2 |
|
Opengvlab/Internvl2-2b |
0.81 |
0.78 |
0.80 |
27 |
1.47 |
|
OpenBMB/Minicpm-V-2_6_bin |
0.75 |
0.77 |
0.78 |
|
|
|
Microsoft/Phi-3-Vision-128K-INSTRUCTION |
0.81 |
0.75 |
0.76 |
29 |
1 |
|
Qwen/qwen2-vl-7b-instruct_bin |
0.73 |
0.74 |
0.75 |
|
|
|
Lava-hf/lava-v1.6-material-7b-hf_bin |
0.67 |
0.71 |
0.72 |
|
|
|
Meta-lama/llama3.2-11b-vision-instruct_bin |
0.72 |
0.70 |
0.71 |
|
|
|
Knowledge of the overall image |
0.73 |
0.70 |
0.70 |
N/a |
57.47 |
|
Opengvlab/Internvl2-2b_bin |
0.70 |
0.63 |
0.65 |
|
|
|
mature-f/glava3-glava3-8b-hf_bin |
0.58 |
0.62 |
0.63 |
|
|
|
Microsoft/Phi-3-Vision-128K-Instruct_bin |
0.27 |
0.22 |
0.21 |
|
|
Main observations:
Impact of the number of classes on closed strategy
We have also investigated how the number of classes affects the performance of the established strategy closed. The results are as follows:
|
model | Number of classes |
10 |
25 |
50 |
75 |
100 |
150 |
200 |
|---|---|---|---|---|---|---|---|
|
Instruction qwen/qwen2-vl-7b |
0.874 |
0.921 |
0.918 |
0.936 |
0.928 |
0.931 |
0.917 |
|
Meta-lama/llama-3.2-11b-vision-stroke |
0.713 |
0.875 |
0.917 |
0.924 |
0.912 |
0.737 |
0.222 |
Main observations:
- The performance of both models generally improves as the number of classes increases by up to 100.
- Beyond 100 classes, performance begins to decline, with a more important decrease observed in meta-wraps/llama-3.2-11b-vision-stroke.
cONcluSiON
The GPT-4o remains a strong contender in the field of vision language models, but open-source models like QWEN2-VL-7B are closing the gap. Our model of recognition of the general image, while fast, lags behind in performance, emphasizing the need for further optimization or adoption of newer architecture. The impact of the number of classes on model performance also underlines the importance of carefully choosing the right model for tasks that include large class groups.





Leave feedback about this