


Calculate the Gini-Simson Diversity Index in SAS
An article by David Corliss in The amstat news (Corliss D. (2025) “Quantity of Diversity: Calculation of the Gini-Simpson Diversity Index) discusses a new statistical measure of diversity that was approved by the US Census Bureau. Statistics is called the Gini-Simson diversity index. The registration bureau has published an article on how to interpret the statistics and how they use it to evaluate the racial and ethnic diversity of the American population (Jensen et al. (2021), “Measuring racial and ethnic diversity for 2020 census”). This blog post shows how to calculate the Gini-Simson diversity index in SAS.
Gini-Simson Diversity Index
There are two diversity statistics that are mathematically equivalent:
- The Simpson Index: Suppose there are groups R. Simpson Index, λ, it is the probability that two articles randomly selected from the sample belong to the same group. For a finite population, let n be sample size and let nI be the size of the subgroup i_th. Then the Simpson Index, λ, is determined by
\ (\ lambda = \ sum \ limits_ {i = 1}^r \ frac {n_i} {n} \ frac {n_i-1} {n-1} \)
- Gini-Sympson Index: This statistic is defined as 1-ALL and estimates the possibility that two items selected by the population do not belong to the same group.
Number of groups, R, called WEALTH of sample. Distribution enI Tells you if the groups are evenly separated. Diversity is a measure of wealth and homogeneity.
By definition, it is clear that if there is only a homogeneous group (R = 1), then λ = 1. If there is a main group and some relatively small groups, then λ will be close to 1. Similarly, if each item belongs to its own group (R = n), then λ = 0.
It is not difficult to draw the formula for the Simpson Index, which is the probability of selecting two items that match the sample randomly. Consider the possibility of drawing two items that are both from the first group. The number of observations for group 1 is N1, so the probability that the first item is from group 1 is N1/n. We do not replace the first article, so now there are N1-1 items in Group 1 and N-1 remaining items in the sample. Therefore, the probability that the second article be from group 1 is (n1-1)/(n-1). The probability of both items be from group 1 is the product (n1/n)*((n1-1)/(n-1)). In a similar way, the probability of both items be from group 2 is (n2/n)*((n2-1)/(n-1)). The continuation of this calculation for all possible groups and the increase of results indicates that λ is the probability that both items are from the same group. Of course, the probability of both items from different groups is supplementary probability, 1 – λ.
Calculate the Gini-Simson Diversity Index in SAS
Calculating the Gini-Simpson diversity index requires that you have a counting vector. That is, you need the counts nI For each subgroup, i = 1, …, r. If you have raw data, you can use Proc FREE to count the number of observations in each subgroup and use the OUT option = in the table statement to write frequencies in a data set, as follows:
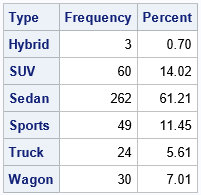
%let RAW_DSNAME = sashelp.cars; /* unsummarized data. Use PROC FREQ to get counts */ %let CAT_VAR = Type; /* categorical variable to analyze */ title "Diversity of the &CAT_VAR Variable in the &RAW_DSNAME Data"; proc freq data=&RAW_DSNAME; tables &CAT_VAR / out=Summary1 nocum; run; |
Intuitively, the type variable is moderately varied. Has n = 428 observations. Of these, 262 (61%) are sedans. If you choose two observations randomly from the data, it is reasonable to expect observations to have the same value, but the exact probability is not clear. The Simpson Index is the exact probability that observations have the same value. The Gini-Sympson index is the exact probability that observations have different values.
Calculating these statistics requires the amount of charges. There are several ways to get the amount, but an easy way to calculate the amount and add it as a new variable is to use SQL Proc.
After adding the amount of counts to the data, it is direct to write a step of SAS data that calculates Simpson and Gini-Sympson diversity statistics as follows:
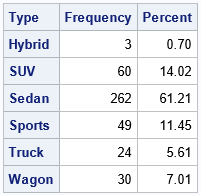
/* the output from PROC FREQ conatins a variable named 'Count'. Add the constant column 'Sum', where Sum=sum(Count) */ proc sql; create table Summary as select *, (select sum(Count) from Summary1) as Sum from Summary1; quit; /* compute the Simpson and Gini-Simpson statistics for &CAT_VAR */ data Diversity; label Sum = "N" SimpsonIndex = "Simpson Index" /* Prob that two items are the same type */ GiniSimpsonIndex = "Gini-Simpson Index"; /* Prob that two items are different types */ retain SimpsonIndex 0; set Summary end=EOF; SimpsonIndex + (Count/Sum) * (Count-1)/(Sum-1); GiniSimpsonIndex = 1 - SimpsonIndex; keep Sum SimpsonIndex GiniSimpsonIndex; if EOF then output; run; proc print data=Diversity label noobs; run; |

Production shows diversity indices for type variable in the Saselp.Cars data group. If you draw two observations randomly, there is a 41.4% chance that they have the same values. Similarly, there is a chance of 58.6% for them to have different values.
If your data is pre-summarized (i.e., you already have the charges for each subgroup), you can remove the step of the process FRERE and continue immediately to the SQL process. I leave that modification as an exercise for the reader.
A macro Sas to calculate the Gini-Simpson Diversity Index
You can include procedures in a macro Sas. The following macro assumes that the data is not coated. You can modify the macro if you have premature numbers.
%macro GiniSimpsonIndex(dsname, cat_var); title "Diversity in the &cat_var Variable in the &dsname Data"; proc freq data=&RAW_DSNAME; tables &CAT_VAR / out=Summary1 nocum; run; /* the output from PROC FREQ conatins a variable named 'Count'. Add the constant column 'Sum', where Sum=sum(Count) */ proc sql; create table Summary as select *, (select sum(Count) from Summary1) as Sum from Summary1; quit; /* compute the Simpson and Gini-Simpson statistics for &CAT_VAR */ data Diversity; label Sum = "N" SimpsonIndex = "Simpson Index" /* Prob that two items are the same type */ GiniSimpsonIndex = "Gini-Simpson Index"; /* Prob that two items are different types */ retain SimpsonIndex 0; set Summary end=EOF; SimpsonIndex + (Count/Sum) * (Count-1)/(Sum-1); GiniSimpsonIndex = 1 - SimpsonIndex; keep Sum SimpsonIndex GiniSimpsonIndex; if EOF then output; run; proc print data=Diversity label noobs; run; title; %mend; %GiniSimpsonIndex(dsname=sashelp.cars, cat_var=Type); |
Production is exactly the same as before and is not shown. Now that you have a macro, you can easily execute the analysis in other data groups or other categorical variables. Here is another example of the origin variable, which has three levels:
%GiniSimpsonIndex(dsname=sashelp.cars, cat_var=Origin); |

Note that the frequency count for the origin variable is approximately. The probability that two randomly selected observations have the same value of origin is 33.5%.
Let’s do a wisdom check by performing a quick calculation of the envelope. For the origin variable, each level contains approximately 1/3 of observations. Let x be a random variable of a discrete uniform for which p (x = ‘a’) = p (x = ‘b’) = p (x = ‘c’) = 1/3. Let’s calculate the probability that two random variants from x are identical. Possible results are AA, AB, AC, BA, BB, BC, CA, CB, and CC, and any event is just as likely. Therefore the probability that two consecutive draws are the same is 1/3. This simpler calculation shows why the Simpson Index is approximately 33.3% for the origin variable. He also points out that for three categories, the “most diverse” arrangement will have a Simpson index that is approximately 0.33 and a Gini-Simpson index that is approximately 0.66.
A SAS IML function to calculate the Gini-Simpson Diversity Index
An advantage of the SAS IML language is that it can perform both row -oriented calculations (such as data step) and column -oriented calculations (such as SQL). The following statements set a function in the SAS IML that calculates the amount, the Simpson Index and the Gini-Simson index for a counting vector. If the data is not pre-summarized, you can use the table subcutaneous to calculate the frequencies for each level of a categorical variable, as follows:
proc iml; /* Compute the Gini-Simpson diversity index Input: Vector of counts (n1, n2, ..., nR) Output: a 1x3 vector. The elements are: N : sum of counts Simpson index of homogeneity Gini-Simpson index of diversity */ start GiniSimpsonIndex(count); Sum = sum(count); SimpsonIndex = sum( (count/Sum) # ((count-1)/(Sum-1)) ); GiniSimpsonIndex = 1 - SimpsonIndex; return Sum || SimpsonIndex || GiniSimpsonIndex; finish; use sashelp.cars; read all var {"Type"}; close; call tabulate(Levels, count, Type); print count(c=Levels); r = GiniSimpsonIndex(count); labls = {"N" "Simpson Index" "Gini-Simpson Index"}; print r(L="" c=labls F=BEST7.); |
The IML function only needs three statements to calculate statistics, but produces the same production as the basic SAS calls to process FREE, PROQL and data step. In IML, you can easily specify the direct count vector. For example, the following statements specify the frequencies of the origin variable in the Saselp.Cars data:
count = {158, 123, 147}; r = GiniSimpsonIndex(count); print r(L="" c=labls F=BEST7.); |

Briefing
The US Census Bureau uses the Gini-Simson index as a measure of diversity. The Gini-Sympson index is the probability that two items (randomly selected by sample) are different types. Equally, the Simpson Index is a measure of homogeneity. The probability that two randomly selected items are the same type. This blog post shows how to calculate the Simpson and Gini-Simson diversity index in SAS. You can use either the base SAS to determine a macro, or you can apply a function to SAS IML. The macro in this article is for uncontrolled (raw) data, but can be modified to support pre-summarized charges.






Leave feedback about this