


Modernize and migrate on-premises fraud detection machine learning workflows to Amazon SageMaker
This post is co-written with Qing Chen and Mark Sinclair from Radial.
Radial is the largest 3PL fulfillment provider, also offering integrated payment, fraud detection, and omnichannel solutions to mid-market and enterprise brands. With over 30 years of industry expertise, Radial tailors its services and solutions to align strategically with each brand’s unique needs.
Radial supports brands in tackling common ecommerce challenges, from scalable, flexible fulfillment enabling delivery consistency to providing secure transactions. With a commitment to fulfilling promises from click to delivery, Radial empowers brands to navigate the dynamic digital landscape with the confidence and capability to deliver a seamless, secure, and superior ecommerce experience.
In this post, we share how Radial optimized the cost and performance of their fraud detection machine learning (ML) applications by modernizing their ML workflow using Amazon SageMaker.
Businesses need for fraud detection models
ML has proven to be an effective approach in fraud detection compared to traditional approaches. ML models can analyze vast amounts of transactional data, learn from historical fraud patterns, and detect anomalies that signal potential fraud in real time. By continuously learning and adapting to new fraud patterns, ML can make sure fraud detection systems stay resilient and robust against evolving threats, enhancing detection accuracy and reducing false positives over time. This post showcases how companies like Radial can modernize and migrate their on-premises fraud detection ML workflows to SageMaker. By using the AWS Experience-Based Acceleration (EBA) program, they can enhance efficiency, scalability, and maintainability through close collaboration.
Challenges of on-premises ML models
Although ML models are highly effective at combating evolving fraud trends, managing these models on premises presents significant scalability and maintenance challenges.
Scalability
On-premises systems are inherently limited by the physical hardware available. During peak shopping seasons, when transaction volumes surge, the infrastructure might struggle to keep up without substantial upfront investment. This can result in slower processing times or a reduced capacity to run multiple ML applications concurrently, potentially leading to missed fraud detections. Scaling an on-premises infrastructure is typically a slow and resource-intensive process, hindering a business’s ability to adapt quickly to increased demand. On the model training side, data scientists often face bottlenecks due to limited resources, forcing them to wait for infrastructure availability or reduce the scope of their experiments. This delays innovation and can lead to suboptimal model performance, putting businesses at a disadvantage in a rapidly changing fraud landscape.
Maintenance
Maintaining an on-premises infrastructure for fraud detection requires a dedicated IT team to manage servers, storage, networking, and backups. Maintaining uptime often involves implementing and maintaining redundant systems, because a failure could result in critical downtime and an increased risk of undetected fraud. Moreover, fraud detection models naturally degrade over time and require regular retraining, deployment, and monitoring. On-premises systems typically lack the built-in automation tools needed to manage the full ML lifecycle. As a result, IT teams must manually handle tasks such as updating models, monitoring for drift, and deploying new versions. This adds operational complexity, increases the likelihood of errors, and diverts valuable resources from other business-critical activities.
Common modernization challenges in ML cloud migration
Organizations face several significant challenges when modernizing their ML workloads through cloud migration. One major hurdle is the skill gap, where developers and data scientists might lack expertise in microservices architecture, advanced ML tools, and DevOps practices for cloud environments. This can lead to development delays, complex and costly architectures, and increased security vulnerabilities. Cross-functional barriers, characterized by limited communication and collaboration between teams, can also impede modernization efforts by hindering information sharing. Slow decision-making is another critical challenge. Many organizations take too long to make choices about their cloud move. They spend too much time thinking about options instead of taking action. This delay can cause them to miss chances to speed up their modernization. It also stops them from using the cloud’s ability to quickly try new things and make changes. In the fast-moving world of ML and cloud technology, being slow to decide can put companies behind their competitors. Another significant obstacle is complex project management, because modernization initiatives often require coordinating work across multiple teams with conflicting priorities. This challenge is compounded by difficulties in aligning stakeholders on business outcomes, quantifying and tracking benefits to demonstrate value, and balancing long-term benefits with short-term goals. To address these challenges and streamline modernization efforts, AWS offers the EBA program. This methodology is designed to assist customers in aligning executives’ vision and resolving roadblocks, accelerating their cloud journey, and achieving a successful migration and modernization of their ML workloads to the cloud.
EBA: AWS team collaboration
EBA is a 3-day interactive workshop that uses SageMaker to accelerate business outcomes. It guides participants through a prescriptive ML lifecycle, starting with identifying business goals and ML problem framing, and progressing through data processing, model development, production deployment, and monitoring.
We recognize that customers have different starting points. For those beginning from scratch, it’s often simpler to start with low code or no code solutions like Amazon SageMaker Canvas and Amazon SageMaker JumpStart, gradually transitioning to developing custom models on Amazon SageMaker Studio. However, because Radial has an existing on-premises ML infrastructure, we can begin directly by using SageMaker to address challenges in their current solution.
During the EBA, experienced AWS ML subject matter experts and the AWS Account Team worked closely with Radial’s cross-functional team. The AWS team offered tailored advice, tackled obstacles, and enhanced the organization’s capacity for ongoing ML integration. Instead of concentrating solely on data and ML technology, the emphasis is on addressing critical business challenges. This strategy helps organizations extract significant value from previously underutilized resources.
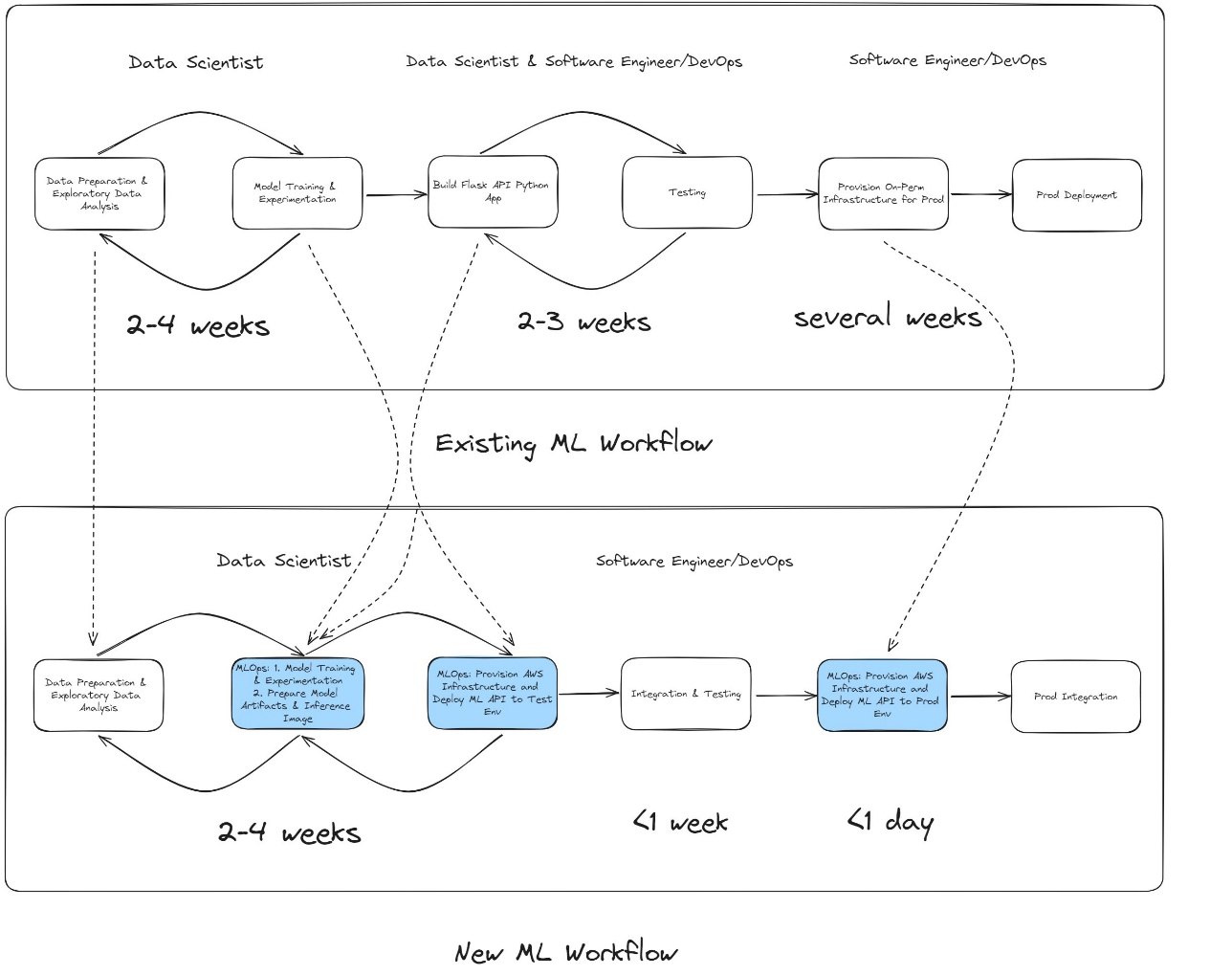
Modernizing ML workflows: From a legacy on-premises data center to SageMaker
Before modernization, Radial hosted its ML applications on premises within its data center. The legacy ML workflow presented several challenges, particularly in the time-intensive model development and deployment processes.
Legacy workflow: On-premises ML development and deployment
When the data science team needed to build a new fraud detection model, the development process typically took 2–4 weeks. During this phase, data scientists performed tasks such as the following:
- Data cleaning and exploratory data analysis (EDA)
- Feature engineering
- Model prototyping and training experiments
- Model evaluation to finalize the fraud detection model
These steps were carried out using on-premises servers, which limited the number of experiments that could be run concurrently due to hardware constraints. After the model was finalized, the data science team handed over the model artifacts and implementation code—along with detailed instructions—to the software developers and DevOps teams. This transition initiated the model deployment process, which involved:
- Provisioning infrastructure – The software team set up the necessary infrastructure to host the ML API in a test environment.
- API implementation and testing – Extensive testing and communication between the data science and software teams were required to make sure the model inference API behaved as expected. This phase typically added 2–3 weeks to the timeline.
- Production deployment – The DevOps and system engineering teams provisioned and scaled on-premises hardware to deploy the ML API into production, a process that could take up to several weeks depending on resource availability.
Overall, the legacy workflow was prone to delays and inefficiencies, with significant communication overhead and a reliance on manual provisioning.
Modern workflow: SageMaker and MLOps
With the migration to SageMaker and the adoption of a machine learning operations (MLOps) architecture, Radial streamlined its entire ML lifecycle—from development to deployment. The new workflow consists of the following stages:
- Model development – The data science team continues to perform tasks such as data cleaning, EDA, feature engineering, and model training within 2–4 weeks. However, with the scalable and on-demand compute resources of SageMaker, they can conduct more training experiments in the same timeframe, leading to improved model performance and faster iterations.
- Seamless model deployment – When a model is ready, the data science team approves it in SageMaker and triggers the MLOps pipeline to deploy the model to the test (pre-production) environment. This eliminates the need for back-and-forth communication with the software team at this stage. Key improvements include:
- The ML API inference code is preconfigured and wrapped by the data scientists during development, providing consistent behavior between development and deployment.
- Deployment to test environments takes minutes, because the MLOps pipeline automates infrastructure provisioning and deployment.
- Final integration and testing – The software team quickly integrates the API and performs necessary tests, such as integration and load testing. After the tests are successful, the team triggers the pipeline to deploy the ML models into production, which takes only minutes.
The MLOps pipeline not only automates the provisioning of cloud resources, but also provides consistency between pre-production and production environments, minimizing deployment risks.
Legacy vs. modern workflow comparison
The new workflow significantly reduces time and complexity:
- Manual provisioning and communication overheads are reduced
- Deployment times are reduced from weeks to minutes
- Consistency between environments provides smoother transitions from development to production
This transformation enables Radial to respond more quickly to evolving fraud trends while maintaining high standards of efficiency and reliability. The following figure provides a visual comparison of the legacy and modern ML workflows.
 Solution overview
Solution overview
When Radial migrated their fraud detection systems to the cloud, they collaborated with AWS Machine Learning Specialists and Solutions Architects to redesign how Radial manage the lifecycle of ML models. By using AWS and integrating continuous integration and delivery (CI/CD) pipelines with GitLab, Terraform, and AWS CloudFormation, Radial developed a scalable, efficient, and secure MLOps architecture. This new design accelerates model development and deployment, so Radial can respond faster to evolving fraud detection challenges.
The architecture incorporates best practices in MLOps, making sure that the different stages of the ML lifecycle—from data preparation to production deployment—are optimized for performance and reliability. Key components of the solution include:
- SageMaker – Central to the architecture, SageMaker facilitates model training, evaluation, and deployment with built-in tools for monitoring and version control
- GitLab CI/CD pipelines – These pipelines automate the workflows for testing, building, and deploying ML models, reducing manual overhead and providing consistent processes across environments
- Terraform and AWS CloudFormation – These services enable infrastructure as code (IaC) to provision and manage AWS resources, providing a repeatable and scalable setup for ML applications
The overall solution architecture is illustrated in the following figure, showcasing how each component integrates seamlessly to support Radial’s fraud detection initiatives.

Account isolation for secure and scalable MLOps
To streamline operations and enforce security, the MLOps architecture is built on a multi-account strategy that isolates environments based on their purpose. This design enforces strict security boundaries, reduces risks, and promotes efficient collaboration across teams. The accounts are as follows:
- Development account (model development workspace) – The development account is a dedicated workspace for data scientists to experiment and develop models. Secure data management is enforced by isolating datasets within Amazon Simple Storage Service (Amazon S3) buckets. Data scientists use SageMaker Studio for data exploration, feature engineering, and scalable model training. When the model build CI/CD pipeline in GitLab is triggered, Terraform and CloudFormation scripts automate the provisioning of infrastructure and AWS resources needed for SageMaker training pipelines. Trained models that meet predefined evaluation metrics are versioned and registered in the Amazon SageMaker Model Registry. With this setup, data scientists and ML engineers can perform multiple rounds of training experiments, review results, and finalize the best model for deployment testing.
- Pre-production account (staging environment) – After a model is validated and approved in the development account, it’s moved to the pre-production account for staging. At this stage, the data science team triggers the model deploy CI/CD pipeline in GitLab to configure the endpoint in the pre-production environment. Model artifacts and inference images are synced from the development account to the pre-production environment. The latest approved model is deployed as an API in a SageMaker endpoint, where it undergoes thorough integration and load testing to validate performance and reliability.
- Production account (live environment) – After passing the pre-production tests, the model is promoted to the production account for live deployment. This account mirrors the configurations of the pre-production environment to maintain consistency and reliability. The MLOps production team triggers the model deploy CI/CD pipeline to launch the production ML API. When it’s live, the model is continuously monitored using Amazon SageMaker Model Monitor and Amazon CloudWatch to make sure it performs as expected. In the event of deployment issues, automated rollback mechanisms revert to a stable model version, minimizing disruptions and maintaining business continuity.
With this multi-account architecture, data scientists can work independently while providing seamless transitions between development and production. The automation of CI/CD pipelines reduces deployment cycles, enhances scalability, and provides the security and performance necessary to maintain effective fraud detection systems.
Data privacy and compliance requirements
Radial prioritizes the protection and security of their customers’ data. As a leader in ecommerce solutions, they are committed to meeting the high standards of data privacy and regulatory compliance such as CPPA and PCI. Radial fraud detection ML APIs process sensitive information such as transaction details and behavioral analytics. To meet strict compliance requirements, they use AWS Direct Connect, Amazon Virtual Private Cloud (Amazon VPC), and Amazon S3 with AWS Key Management Service (AWS KMS) encryption to build a secure and compliant architecture.
Protecting data in transit with Direct Connect
Data is never exposed to the public internet at any stage. To maintain the secure transfer of sensitive data between on-premises systems and AWS environments, Radial uses Direct Connect, which offers the following capabilities:
- Dedicated network connection – Direct Connect establishes a private, high-speed connection between the data center and AWS, alleviating the risks associated with public internet traffic, such as interception or unauthorized access
- Consistent and reliable performance – Direct Connect provides consistent bandwidth and low latency, making sure fraud detection APIs operate without delays, even during peak transaction volumes
Isolating workloads with Amazon VPC
When data reaches AWS, it’s processed in a VPC for maximum security. This offers the following benefits:
- Private subnets for sensitive data – The components of the fraud detection ML API, including SageMaker endpoints and AWS Lambda functions, reside in private subnets, which are not accessible from the public internet
- Controlled access with security groups – Strict access control is enforced through security groups and network access control lists (ACLs), allowing only authorized systems and users to interact with VPC resources
- Data segregation by account – As mentioned previously regarding the multi-account strategy, workloads are isolated across development, staging, and production accounts, each with its own VPC, to limit cross-environment access and maintain compliance.
Securing data at rest with Amazon S3 and AWS KMS encryption
Data involved in the fraud detection workflows (for both model development and real-time inference) is securely stored in Amazon S3, with encryption powered by AWS KMS. This offers the following benefits:
- AWS KMS encryption for sensitive data – Transaction logs, model artifacts, and prediction results are encrypted at rest using managed KMS keys
- Encryption in transit – Interactions with Amazon S3, including uploads and downloads, are encrypted to make sure data remains secure during transfer
- Data retention policies – Lifecycle policies enforce data retention limits, making sure sensitive data is stored only as long as necessary for compliance and business purposes before scheduled deletion
Data privacy by design
Data privacy is integrated into every step of the ML API workflow:
- Secure inference – Incoming transaction data is processed within VPC-secured SageMaker endpoints, making sure predictions are made in a private environment
- Minimal data retention – Real-time transaction data is anonymized where possible, and only aggregated results are stored for future analysis
- Access control and governance – Resources are governed by AWS Identity and Access Management (IAM) policies, making sure only authorized personnel and services can access data and infrastructure
Benefits of the new ML workflow on AWS
To summarize, the implementation of the new ML workflow on AWS offers several key benefits:
- Dynamic scalability – AWS enables Radial to scale their infrastructure dynamically to handle spikes in both model training and real-time inference traffic, providing optimal performance during peak periods.
- Faster infrastructure provisioning – The new workflow accelerates the model deployment cycle, reducing the time to provision infrastructure and deploy new models by up to several weeks.
- Consistency in model training and deployment – By streamlining the process, Radial achieves consistent model training and deployment across environments. This reduces communication overhead between the data science team and engineering/DevOps teams, simplifying the implementation of model deployment.
- Infrastructure as code – With IaC, they benefit from version control and reusability, reducing manual configurations and minimizing the risk of errors during deployment.
- Built-in model monitoring – The built-in capabilities of SageMaker, such as experiment tracking and data drift detection, help them maintain model performance and provide timely updates.
Key takeaways and lessons learned from Radial’s ML model migration
To help modernize your MLOps workflow on AWS, the following are a few key takeaways and lessons learned from Radial’s experience:
- Collaborate with AWS for customized solutions – Engage with AWS to discuss your specific use cases and identify templates that closely match your requirements. Although AWS offers a wide range of templates for common MLOps scenarios, they might need to be customized to fit your unique needs. Explore how to adapt these templates for migrating or revamping your ML workflows.
- Iterative customization and support – As you customize your solution, work closely with both your internal team and AWS Support to address any issues. Plan for execution-based assessments and schedule workshops with AWS to resolve challenges at each stage. This might be an iterative process, but it makes sure your modules are optimized for your environment.
- Use account isolation for security and collaboration – Use account isolation to separate model development, pre-production, and production environments. This setup promotes seamless collaboration between your data science team and DevOps/MLOps team, while also enforcing strong security boundaries between environments.
- Maintain scalability with proper configuration – Radial’s fraud detection models successfully handled transaction spikes during peak seasons. To maintain scalability, configure instance quota limits correctly within AWS, and conduct thorough load testing before peak traffic periods to avoid any performance issues during high-demand times.
- Secure model metadata sharing – Consider opting out of sharing model metadata when building your SageMaker pipeline to make sure your aggregate-level model information remains secure.
- Prevent image conflicts with proper configuration – When using an AWS managed image for model inference, specify a hash digest within your SageMaker pipeline. Because the latest hash digest might change dynamically for the same image model version, this step helps avoid conflicts when retrieving inference images during model deployment.
- Fine-tune scaling metrics through load testing – Fine-tune scaling metrics, such as instance type and automatic scaling thresholds, based on proper load testing. Simulate your business’s traffic patterns during both normal and peak periods to confirm your infrastructure scales effectively.
- Applicability beyond fraud detection – Although the implementation described here is tailored to fraud detection, the MLOps architecture is adaptable to a wide range of ML use cases. Companies looking to modernize their MLOps workflows can apply the same principles to various ML projects.
Conclusion
This post demonstrated the high-level approach taken by Radial’s fraud team to successfully modernize their ML workflow by implementing an MLOps pipeline and migrating from on premises to the AWS Cloud. This was achieved through close collaboration with AWS during the EBA process. The EBA process begins with 4–6 weeks of preparation, culminating in a 3-day intensive workshop where a minimum viable MLOps pipeline is created using SageMaker, Amazon S3, GitLab, Terraform, and AWS CloudFormation. Following the EBA, teams typically spend an additional 2–6 weeks to refine the pipeline and fine-tune the models through feature engineering and hyperparameter optimization before production deployment. This approach enabled Radial to effectively select relevant AWS services and features, accelerating the training, deployment, and testing of ML models in a pre-production SageMaker environment. As a result, Radial successfully deployed multiple new ML models on AWS in their production environment around Q3 2024, achieving a more than 75% reduction in ML model deployment cycle and a 9% improvement in overall model performance.
“In the ecommerce retail space, mitigating fraudulent transactions and enhancing consumer experiences are top priorities for merchants. High-performing machine learning models have become invaluable tools in achieving these goals. By leveraging AWS services, we have successfully built a modernized machine learning workflow that enables rapid iterations in a stable and secure environment.”
– Lan Zhang, Head of Data Science and Advanced Analytics
To learn more about EBAs and how this approach can benefit your organization, reach out to your AWS Account Manager or Customer Solutions Manager. For additional information, refer to Using experience-based acceleration to achieve your transformation and Get to Know EBA.
About the Authors
 Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, Natural Language Processing, and Deep Learning. He assists Enterprise customers in achieving modernization and scalable deployment in the Cloud. Beyond the tech world, Jake finds delight in skateboarding, hiking, and piloting air drones.
Jake Wen is a Solutions Architect at AWS, driven by a passion for Machine Learning, Natural Language Processing, and Deep Learning. He assists Enterprise customers in achieving modernization and scalable deployment in the Cloud. Beyond the tech world, Jake finds delight in skateboarding, hiking, and piloting air drones.
 Qing Chen is a senior data scientist at Radial, a full-stack solution provider for ecommerce merchants. In his role, he modernizes and manages the machine learning framework in the payment & fraud organization, driving a solid data-driven fraud decisioning flow to balance risk & customer friction for merchants.
Qing Chen is a senior data scientist at Radial, a full-stack solution provider for ecommerce merchants. In his role, he modernizes and manages the machine learning framework in the payment & fraud organization, driving a solid data-driven fraud decisioning flow to balance risk & customer friction for merchants.
 Mark Sinclair is a senior cloud architect at Radial, a full-stack solution provider for ecommerce merchants. In his role, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering systems, driving a solid engineering architecture and workflow to provide highly scalable transactional services for Radial clients.
Mark Sinclair is a senior cloud architect at Radial, a full-stack solution provider for ecommerce merchants. In his role, he designs, implements and manages the cloud infrastructure and DevOps for Radial engineering systems, driving a solid engineering architecture and workflow to provide highly scalable transactional services for Radial clients.







Leave feedback about this