Your questions were answered: How to succeed in the generating using llmops and agents
The generator is one of the most interesting technologies – and misunderstood – there now. Everyone knows the chatgt, but when it comes to applying Genai to business, things can be complicated. Many projects are stuck because they are too wide or do not have a clearly defined purpose. While a chatbot with general goals can work for casual use, business applications need to be much more intended-and much more accurate.
Think about it: you can forgive chatgpt for giving you a strange film recommendation, but would you feel the same if that of your company gave a client the wrong reimbursement policy or sensitive information exposed?
That is why building Genai tools that actually work in the real world means narrowing your focus, get your data in shape, and set clear expectations about what success seems. It’s not just about a delightful application of it – it’s about what gives useful, important and responsible answers.
In this Q&A, we will walk through some of the most common questions we hear from teams that try to remove Genai from the ground – from why they use cases of matter, to the way he adapted, how you can protect the data and monitor for prejudice. Whether you are just starting or looking to optimize, this guide is created to help you avoid the usual traps and build something your users can actually trust.
Q: Why use use issues?
Answer: When planning a Genai project, the first advantage should always be designing a narrow and well -defined use case.
On one occasion defined, the two main best practices for the team include:
- Cure of thoughtful and deliberate data for good adjustment for the case of use
- Developing a Golden Standard List of Estimated Requests and Answers Entering within the Matter of Use
Good adjustment data should be explored using techniques such as modeling the topics and profiling the text to better understand the content and ensure that it actually contains information that is important for the case of use. Duplication, noise and uncertainty can be addressed using liti patterns.
Once good tuning data are appropriately cured, time can be spent on developing fast -paced pairs of golden standard and response couples. These couples should not be exhaustive, but should cover a series of actions that you expect your users to take. Having fast pairs/documented response provides an initial basis for working on tasks such as developing red team scenarios and evaluating the quality of responses. Without an initial base to compare against, it can be difficult to evaluate how well the model is performing.
Q: Speaking of models, how can you define the best model for your use case?
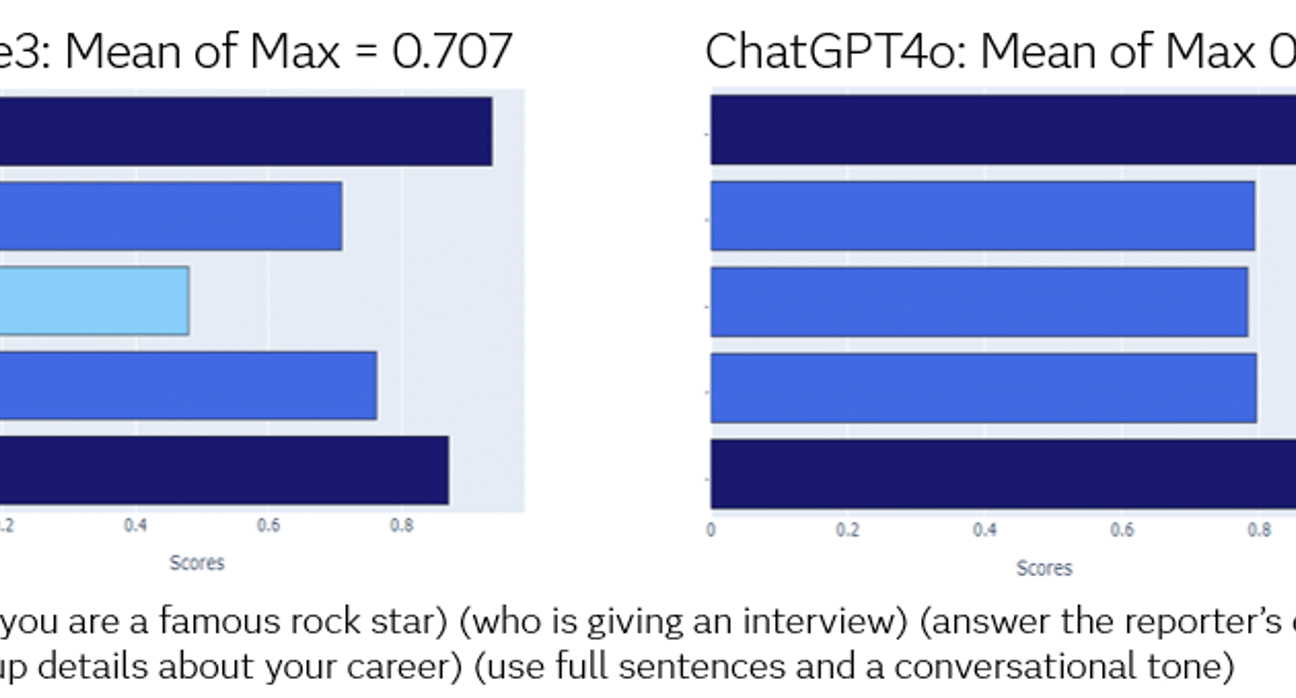
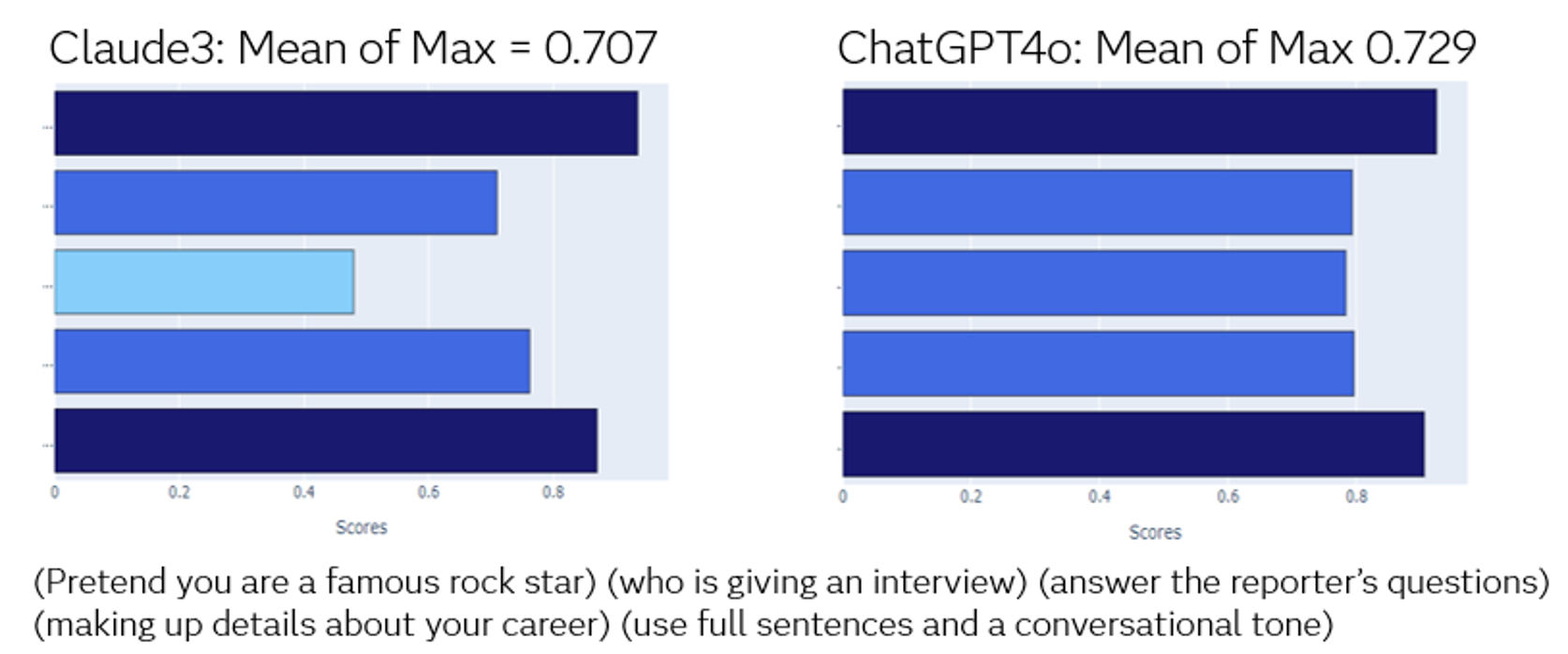
Answer: Another benefit of having a standard golden group of fast couples/response is that you can try your instructions on multiple models and assess how comprehensive the model responds to different types of requirements. Some models may be more suitable for the style of requirements that address the case of your use. This gets some of the assumptions from choosing the model.

Question: What should you consider in trying to ensure the end -user promoter?
Answer: There are many moving parts in a generating work flow, but from a end user perspective, it starts with a fast and ends with what we hope is a response that the user uses. Speed opens up a path that can present a variety of challenges. There are users who have a difficult time to get the information they are looking for from a search engine. This problem is complicated through LLM requirements and may be further complicated by the fact that LLM we usually use are optimized for English speakers.
- What if our users do not speak English as their first language?
- What if our users are dyslexic or have other disabilities that affect the way they create words on the computer?
- What if our users prefer to promote the use of shorts like them when making messages (Brb, IRL, LOL,: D)?
Our users will come from a variety of descent, academic, cultural and technically, so we need to consider this and develop ways to level the playing field, so all users have an opportunity to have a similar experience.
With our strengths in comparison of text and similarity evaluation, we can compare a quick user with the standard golden instructions group, assess if it is quickly similar to one of the standards, then we offer users the choice to execute their fast AS-IS or accept the Standard Gold Prompt.
Q: What are the agents and how do they fit these scenarios?
Answer: The agents of it are systems created to process information and take action to achieve specific goals. Most of us are familiar with the reactive agents of him, such as traditional, pre-chatbot applications, where users are in the garden for response garden through the written rules and answers. Cognitive agents use deep learning to adapt to new information, such as chatgpt. Autonomous agents make decisions without human contribution, such as cars they drive.
All agents are created to automate the tasks of efficiency benefits, but there is much attention currently paid to the idea of autonomous agents, which brings us to the next question and be able to monitor the content of the text exposed and submitted by LLM.
Q: How to store private and sensitive data?
Answer: Because LLMs are so convenient and friendly, some users may not understand that organizational standards and protective measures against personally identifiable information compromise and others apply when using them. In our experience, many users have agreed to copy and glue sensitive information to their instructions. It is important to have an agent of one who stands by to intercede private or sensitive information before presenting with the model. This, and monitoring for toxicity and prejudice can help protect organizations from some of the operational risks associated with LLM.
Q: Why monitor for toxicity and prejudice?
Answer: LLM are exposed to toxicity and prejudice in preceding data. Because there is a lack of transparency in most LLMs in relation to preliminary data, it is difficult to evaluate the LLM of prejudice and toxicity. Most content monitoring APs outside the box prevent LLM from providing answers that are clearly toxic or biased, but toxicity and prejudice can be delicate, like dog whistles. Some cases of use will be more likely to be encountered or affected by toxicity and prejudice. Because you know your case of use, you need to understand where toxicity and prejudice can occur. You can go beyond monitoring the contents outside the box and set up an agent that requires models in the answers that can affect your users.
It is also important to admit that bad actors are everywhere and often use rapid injections with malicious intention to force the bad. Bad actors can use a series of toxic or biased requirements to manipulate the model. An AI agent can be used to look for models that indicate that a user can try to use the model in inappropriate or unfair ways.
Q: Do you need to consider the sense assessment of the model’s answers?
Answer: Absolutely, the tone of model responses is important. In many cases the tone should be neutral, although depending on the style of the world, they may be more positive or negative. You do not want an answer that gives bad news – as a denial of credit to have a very loving tone. Likewise, you do not want an answer that gives good news – like your last blood work was all within the range to have a gloomy punishment and tone. Having the opportunity to provide a suitable tone of response is vital to a good user experience. Having an agent he in the process that can evaluate the feeling of answers can help provide a good user experience.
Q: Why is it important for users to stay in office?
Answer: One last point, sometimes you need to redirect users again in the case of use. Given an open dialog box, some users will ask questions that are not important, and the app was not created to answer. They can look for benign things for the weather or lunch recommendations. He can be decided to filter specific insignificant requirements. One of the main benefits of this is to reduce the costs of the sign. The agent may intercept insignificant requests and issue a message to the user to put them in office. While a different subject than evaluating the requirements for toxicity or prejudice, the general premise is the same.
Q: How do you know that your chosen model is performing well?
Answer: We have already talked about measuring the inclusion of responses to requirements as a way to choose a model that will perform well in certain styles of requirements, but there are other points of accuracy and importance to consider in the field of evaluation.
Let’s start accurately. At the end of the day, you need to trust that your model is answering the questions correctly. If you have a model that only receives the answer immediately half the time, it will not be very useful.
Next, if you have created a great use case, you admit that many users will ask the same question or the same type of question more than once. It is important for the model to return the answers that are similar and durable. You would not want to have a reliable human domain expert who answers the same questions from different teammates with a different answer. The same is true for your LLM. They should be able to answer the same or similar questions in a steady way.
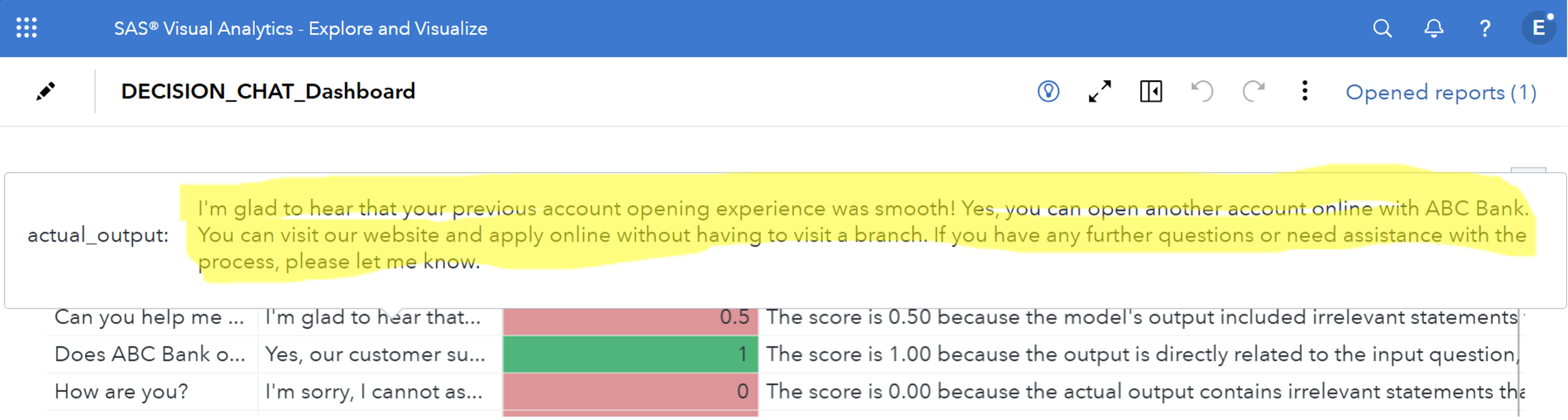
We can also see the importance of the answer. Importance is more than just an accurate answer. It is an accurate and concise response. We do not want our business bots to be poetic wax on topics – they have to reach the point because users do not have time to read a long answer, and organizations do not want to pay for the extra signs. In the example in the following dashboard, the pronounced response is considered irrelevant because it determines and contains unnecessary information.

Genai’s impact will continue to grow and you have the opportunity to be part of this developing technology. While more projects are determined and developed, they will undergo increasing control. If you set up an app you expect to be supported for information, you should get it right, or users will abandon it. Understanding your options, technology and using these strategies to help will increase your chances of success and your ability to try a successful roi!