Deep Studying With out Labels | Microsoft Study
Saying new open supply contributions to the Apache Spark neighborhood for creating deep, distributed, object detectors – and not using a single human-generated label
This publish is authored by members of the Microsoft ML for Apache Spark Crew – Mark Hamilton, Minsoo Thigpen,
Abhiram Eswaran, Ari Inexperienced, Courtney Cochrane, Janhavi Suresh Mahajan, Karthik Rajendran, Sudarshan Raghunathan, and Anand Raman.
In at present’s day and age, if knowledge is the brand new oil, labelled knowledge is the brand new gold.
Right here at Microsoft, we regularly spend loads of our time occupied with “Massive Information” points, as a result of these are the best to unravel with deep studying. Nevertheless, we regularly overlook the way more ubiquitous and troublesome issues which have little to no knowledge to coach with. On this work we are going to present how, even with none knowledge, one can create an object detector for nearly something discovered on the net. This successfully bypasses the expensive and useful resource intensive processes of curating datasets and hiring human labelers, permitting you to leap on to clever fashions for classification and object detection fully in sillico.
We apply this system to assist monitor and shield the endangered inhabitants of snow leopards.
This week on the Spark + AI Summit in Europe, we’re excited to share with the neighborhood, the next thrilling additions to the Microsoft ML for Apache Spark Library that make this workflow simple to duplicate at large scale utilizing Apache Spark and Azure Databricks:
- Bing on Spark: Makes it simpler to construct purposes on Spark utilizing Bing search.
- LIME on Spark: Makes it simpler to deeply perceive the output of Convolutional Neural Networks (CNN) fashions skilled utilizing SparkML.
- Excessive-performance Spark Serving: Improvements that allow ultra-fast, low latency serving utilizing Spark.
We illustrate the right way to use these capabilities utilizing the Snow Leopard Conservation use case, the place machine studying is a key ingredient in the direction of constructing highly effective picture classification fashions for figuring out snow leopards from pictures.
Use Case – The Challenges of Snow Leopard Conservation
Snow leopards are going through a disaster. Their numbers are dwindling because of poaching and mining, but little is thought about the right way to finest shield them. A part of the problem is that there are solely about 4 thousand to seven thousand particular person animals inside a possible 1.5 million sq. kilometer vary. As well as, Snow Leopard territory is in a few of the most distant, rugged mountain ranges of central Asia, making it close to unimaginable to get there with out backpacking tools.

Determine 1: Our staff’s second flat tire on the way in which to snow leopard territory.
To actually perceive the snow leopard and what influences its survival charges, we’d like extra knowledge. To this finish, we now have teamed up with the Snow Leopard Belief to assist them collect and perceive snow leopard knowledge. “Since visible surveying just isn’t an possibility, biologists deploy motion-sensing cameras in snow leopard habitats that seize pictures of snow leopards, prey, livestock, and anything that strikes,” explains Rhetick Sengupta, Board President of Snow Leopard Belief. “They then must type by the pictures to seek out those with snow leopards with the intention to be taught extra about their populations, conduct, and vary.” Through the years these cameras have produced over 1 million pictures. The Belief can use this data to determine new protected areas and enhance their community-based conservation efforts.
Nevertheless, the issue with camera-trap knowledge is that the biologists should type by all the pictures to tell apart pictures of snow leopards and their prey from pictures which have neither. “Guide picture sorting is a time-consuming and dear course of,” Sengupta says. “Actually, it takes round 300 hours per digicam survey. As well as, knowledge assortment practices have modified through the years.”
We now have labored to assist automate the Belief’s snow leopard detection pipeline with Microsoft Machine Studying for Apache Spark (MMLSpark). This consists of each classifying snow leopard pictures, in addition to extracting detected leopards to determine and match to a big database of identified leopard people.
Step 1: Gathering Information
Gathering knowledge is usually the toughest a part of the machine studying workflow. With out a big, high-quality dataset, a challenge is probably going by no means to get off the bottom. Nevertheless, for a lot of duties, making a dataset is extremely troublesome, time consuming, or downright unimaginable. We have been lucky to work with the Snow Leopard Belief who’ve already gathered 10 years of digicam lure knowledge and have meticulously labelled hundreds of pictures. Nevertheless, the belief can not launch this knowledge to the general public, as a consequence of dangers from poachers who use picture metadata to pinpoint leopards within the wild. Consequently, if you’re seeking to create your individual Snow Leopard evaluation, it is advisable to begin from scratch.


Determine 2: Examples of digicam lure pictures from the Snow Leopard Belief’s dataset.
Saying: Bing on Spark
Confronted with the problem of making a snow leopard dataset from scratch, it is arduous to know the place to start out. Amazingly, we needn’t go to Kyrgyzstan and arrange a community of movement delicate cameras. We have already got entry to one of many richest sources of human information on the planet – the web. The instruments that we now have created over the previous 20 years that index the web’s content material not solely assist people be taught in regards to the world however may assist the algorithms we create do the identical.
In the present day we’re releasing an integration between the Azure Cognitive Companies and Apache Spark that allows querying Bing and plenty of different clever providers at large scales. This integration is a part of the Microsoft ML for Apache Spark (MMLSpark) open supply challenge. The Cognitive Companies on Spark make it simple to combine intelligence into your current Spark and SQL workflows on any cluster utilizing Python, Scala, Java, or R. Below the hood, every Cognitive Service on Spark leverages Spark’s large parallelism to ship streams of requests as much as the cloud. As well as, the combination between SparkML and the Cognitive Companies makes it simple to compose providers with different fashions from the SparkML, CNTK, TensorFlow, and LightGBM ecosystems.


Determine 3: Outcomes for Bing snow leopard picture search.
We are able to use Bing on Spark to rapidly create our personal machine studying datasets that includes something we are able to discover on-line. To create a customized snow leopard dataset takes solely two distributed queries. The primary question creates the “constructive class” by pulling the primary 80 pages of the “snow leopard” picture outcomes. The second question creates the “adverse class” to check our leopards towards. We are able to carry out this search in two alternative ways, and we plan to discover them each in upcoming posts. Our first possibility is to seek for pictures that will seem like the sorts of pictures we shall be getting out within the wild, corresponding to empty mountainsides, mountain goats, foxes, grass, and so on. Our second possibility attracts inspiration from Noise Contrastive Estimation, a mathematical method used ceaselessly within the Phrase Embedding literature. The essential thought behind noise contrastive estimation is to categorise our snow leopards towards a big and numerous dataset of random pictures. Our algorithm shouldn’t solely be capable to inform a snow leopard from an empty picture, however from all kinds of different objects within the visible world. Sadly, Bing Pictures doesn’t have a random picture API we might use to make this dataset. As a substitute, we are able to use random queries as a surrogate for random sampling from Bing. Producing hundreds of random queries is surprisingly simple with one of many multitude of on-line random phrase turbines. As soon as we generate our phrases, we simply must load them right into a distributed Spark DataFrame and move them to Bing Picture Search on Spark to seize the primary 10 pictures for every random question.
With these two datasets in hand, we are able to add labels, sew them collectively, dedupe, and obtain the picture bytes to the cluster. SparkSQL parallelizes this course of and may pace up the obtain by orders of magnitude. It solely takes a couple of seconds on a big Azure Databricks cluster to drag hundreds of pictures from world wide. Moreover, as soon as the pictures are downloaded, we are able to simply preprocess and manipulate them with instruments like OpenCV on Spark.


Determine 4: Diagram exhibiting the right way to create a labelled dataset for snow leopard classification utilizing Bing on Spark.
Step 2: Making a Deep Studying Classifier
Now that we now have a labelled dataset, we are able to start occupied with our mannequin. Convolutional neural networks (CNNs) are at present’s state-of-the-art statistical fashions for picture evaluation. They seem in every little thing from driverless automobiles, facial recognition programs, and picture search engines like google and yahoo. To construct our deep convolution community, we used MMLSpark, which offers easy-to-use distributed deep studying with the Microsoft Cognitive Toolkit on Spark.
MMLSpark makes it particularly simple to carry out distributed switch studying, a deep studying method that mirrors how people be taught new duties. Once we be taught one thing new, like classifying snow leopards, we do not begin by re-wiring our total mind. As a substitute, we depend on a wealth of prior information gained over our lifetimes. We solely want a couple of examples, and we rapidly develop into excessive accuracy snow leopard detectors. Amazingly switch studying creates networks with comparable conduct. We start by utilizing a Deep Residual Community that has been skilled on thousands and thousands of generic pictures. Subsequent, we reduce off a couple of layers of this community and change them with a SparkML mannequin, like Logistic Regression, to be taught a last mapping from deep options to snow leopard possibilities. Consequently, our mannequin leverages its earlier information within the type of clever options and may adapt itself to the duty at hand with the ultimate SparkML Mannequin. Determine 5 reveals a schematic of this structure.
With MMLSpark, it is also simple so as to add enhancements to this fundamental structure like dataset augmentation, class balancing, quantile regression with LightGBM on Spark, and ensembling. To be taught extra, discover our journal paper on this work, or attempt the instance on our web site.
It is vital to keep in mind that our algorithm can be taught from knowledge sourced fully from Bing. It didn’t want hand labeled knowledge, and this methodology is relevant to nearly any area the place a picture search engine can discover your pictures of curiosity.


Determine 5: A diagram of switch studying with ResNet50 on Spark.
Step 3: Creating an Object Detection Dataset with Distributed Mannequin Interpretability
At this level, we now have proven the right way to create a deep picture classification system that leverages Bing to remove the necessity for labelled knowledge. Classification programs are extremely helpful for counting the variety of sightings. Nevertheless, classifiers inform us nothing about the place the leopard is within the picture, they solely return a likelihood {that a} leopard is in a picture. What may appear to be a delicate distinction, can actually make a distinction in an finish to finish software. For instance, understanding the place the leopard is can assist people rapidly decide whether or not the label is appropriate. It can be useful for conditions the place there could be a couple of leopard within the body. Most significantly for this work, to grasp what number of particular person leopards stay within the wild, we have to cross match particular person leopards throughout a number of cameras and places. Step one on this course of is cropping the leopard pictures in order that we are able to use wildlife matching algorithms like HotSpotter.
Ordinarily, we would want labels to coach an object detector, aka painstakingly drawn bounding containers round every leopard picture. We might then prepare an object detection community be taught to breed these labels. Sadly, the pictures we pull from Bing don’t have any such bounding containers hooked up to them, making this job appear unimaginable.
At this level we’re so shut, but to date. We are able to create a system to find out whether or not a leopard is within the picture, however not the place the leopard is. Fortunately, our bag of machine studying tips just isn’t but empty. It could be preposterous if our deep community couldn’t find the leopard. How might something reliably know that there’s a snow leopard within the picture with out seeing it immediately? Positive, the algorithm might concentrate on combination picture statistics just like the background or the lighting to make an informed guess, however leopard detector ought to know a leopard when it sees it. If our mannequin understands and makes use of this data, the query is “How can we peer into our mannequin’s thoughts to extract this data?”.
Fortunately, Marco Tulio Ribeiro and a staff of researchers on the College of Washington have created an methodology known as LIME (Native Interpretable Mannequin Agnostic Explanations), for explaining the classifications of any picture classifier. This methodology permits us to ask our classifier a sequence of questions, that when studied in combination, will inform us the place the classifier is trying. What’s most enjoyable about this methodology, is that it makes no assumptions in regards to the sort of mannequin beneath investigation. You may clarify your individual deep community, a proprietary mannequin like these discovered within the Microsoft cognitive providers, or perhaps a (very affected person) human classifier. This makes it broadly relevant not simply throughout fashions, but in addition throughout domains.


Determine 6: Diagram exhibiting the method for decoding a picture classifier.
Determine 6 reveals a visible illustration of the LIME course of. First, we are going to take our authentic picture, and break it into “interpretable parts” known as “superpixels”. Extra particularly, superpixels are clusters of pixels that teams pixels which have an identical colour and placement collectively. We then take our authentic picture and randomly perturb it by “turning off” random superpixels. This ends in hundreds of latest pictures which have elements of the leopard obscured. We are able to then feed these perturbed pictures by our deep community to see how our perturbations have an effect on our classification possibilities. These fluctuations in mannequin possibilities assist level us to the superpixels of the picture which can be most vital for the classification. Extra formally, we are able to match a linear mannequin to a brand new dataset the place the inputs are binary vectors of superpixel on/off states, and the targets are the possibilities that the deep community outputs for every perturbed picture. The realized linear mannequin weights then present us which superpixels are vital to our classifier. To extract an evidence, we simply want to take a look at a very powerful superpixels. In our evaluation, we use these which can be within the prime ~80% of superpixel importances.
LIME provides us a method to peer into our mannequin and decide the precise pixels it’s leveraging to make its predictions. For our leopard classifier, these pixels typically immediately spotlight the leopard within the body. This not solely provides us confidence in our mannequin, but in addition offering us with a method to generate richer labels. LIME permits us to refine our classifications into bounding containers for object detection by drawing rectangles across the vital superpixels. From our experiments, the outcomes have been strikingly near what a human would draw across the leopard.


Determine 7: LIME pixels monitoring a leopard because it strikes by the mountains
Saying: LIME on Spark
LIME has superb potential to assist customers perceive their fashions and even robotically create object detection datasets. Nevertheless, LIME’s main downside is its steep computational value. To create an interpretation for only one picture, we have to pattern hundreds of perturbed pictures, move all of them by our community, after which prepare a linear mannequin on the outcomes. If it takes 1 hour to guage your mannequin on a dataset, then it might take at the very least 50 days of computation to transform these predictions to interpretations. To assist make this course of possible for big datasets, we’re releasing a distributed implementation of LIME as a part of MMLSpark. This can allow customers to rapidly interpret any SparkML picture classifier, together with these backed by deep community frameworks like CNTK or TensorFlow. This helps make complicated workloads just like the one described, doable in only some traces of MMLSpark code. If you need to attempt the code, please see our instance pocket book for LIME on Spark.




Determine 8: Left: Define of most vital LIME superpixels. Proper: instance of human-labeled bounding field (blue) versus the LIME output bounding field (yellow)
Step 4: Transferring LIME’s Data right into a Deep Object Detector
By combining our deep classifier with LIME, we now have created a dataset of leopard bounding containers. Moreover, we completed this with out having to manually classify or labelling any pictures with bounding containers. Bing Pictures, Switch Studying, and LIME have carried out all of the arduous work for us. We are able to now use this labelled dataset to be taught a devoted deep object detector able to approximating LIME’s outputs at a 1000x speedup. Lastly, we are able to deploy this quick object detector as an internet service, telephone app, or real-time streaming software for the Snow Leopard Belief to make use of.
To construct our Object Detector, we used the TensorFlow Object Detection API. We once more used deep switch studying to fine-tune a pre-trained Sooner-RCNN object detector. This detector was pre-trained on the Microsoft Widespread Objects in Context (COCO) object detection dataset. Similar to switch studying for deep picture classifiers, working with an already clever object detector dramatically improves efficiency in comparison with studying from scratch. In our evaluation we optimized for accuracy, so we determined to make use of a Sooner R-CNN community with an Inception Resnet v2. Determine 9 reveals speeds and performances of a number of community architectures, FRCNN + Inception Resnet V2 fashions are likely to cluster in the direction of the excessive accuracy aspect of the plot.
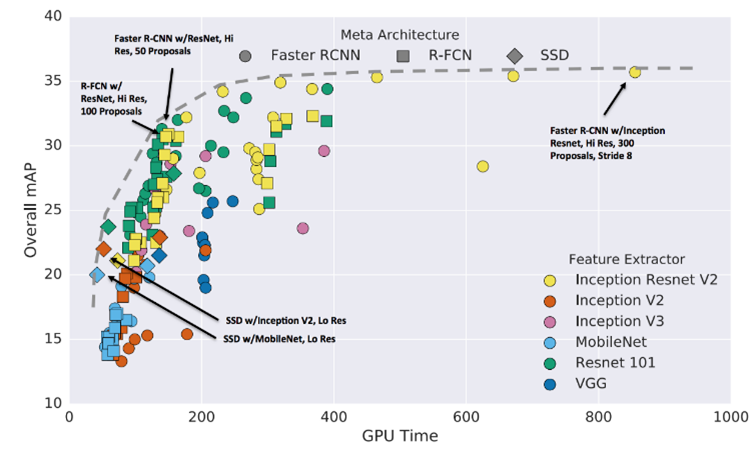

Determine 9: Velocity/accuracy tradeoffs for contemporary convolutional object detectors. (Supply: Google Analysis.)
Outcomes
We discovered that Sooner R-CNN was capable of reliably reproduce LIME’s outputs in a fraction of the time. Determine 10 reveals a number of normal pictures from the Snow Leopard Belief’s dataset. On these pictures, Sooner R-CNN’s outputs immediately seize the leopard within the body and match close to completely with human curated labels.


Determine 10: A comparability of human labeled pictures (left) and the outputs of the ultimate skilled Sooner-RCNN on LIME predictions (proper).


Determine 11: A comparability of adverse human labeled pictures (left) and the outputs of the ultimate skilled Sooner-RCNN on LIME predictions (proper).
Nevertheless, some pictures nonetheless pose challenges to this methodology. In Determine 11, we study a number of errors made by the article detector. Within the prime picture, there are two discernable leopards within the body, nevertheless Sooner R-CNN is barely capable of detect the bigger leopard. That is because of the methodology used to transform LIME outputs to bounding containers. Extra particularly, we use a easy methodology that bounds all chosen superpixels with a single rectangle. Consequently, our bounding field dataset has at most one field per picture. To refine this process, one might probably cluster the superpixels to determine if there are a couple of object within the body, then draw the bounding containers. Moreover, some leopards are troublesome to identify as a consequence of their camouflage and so they slip by the detector. A part of this have an effect on could be as a consequence of anthropic bias in Bing Search. Particularly, Bing Picture Search returns solely the clearest photos of leopards and these pictures are a lot simpler than your common digicam lure picture. To mitigate this impact, one might interact in rounds of arduous adverse mining, increase the Bing knowledge with arduous to see leopards, and upweight these examples which present troublesome to identify leopards.
Step 5: Deployment as a Internet Service
The ultimate stage in our challenge is to deploy our skilled object detector in order that the Snow Leopard belief can get mannequin predictions from wherever on the earth.
Saying: Sub-millisecond Latency with Spark Serving
In the present day we’re excited to announce a brand new platform for deploying Spark Computations as distributed net providers. This framework, known as Spark Serving, dramatically simplifies the serving course of in Python, Scala, Java and R. It provides ultra-low latency providers backed by a distributed and fault-tolerant Spark Cluster. Below the hood, Spark Serving takes care of spinning up and managing net providers on every node of your Spark cluster. As a part of the discharge of MMLSpark v0.14, Spark Serving noticed a 100-fold latency discount and may now deal with responses inside a single millisecond.


Determine 12: Spark Serving latency comparability.
We are able to use this framework to take our deep object detector skilled with Horovod on Spark, and deploy it with only some traces of code. To attempt deploying a SparkML mannequin as an internet service for your self, please see our pocket book instance.
Future Work
The subsequent step of this challenge is to make use of this leopard detector to create a worldwide database of particular person snow leopards and their sightings throughout places. We plan to make use of a instrument known as HotSpotter to robotically determine particular person leopards utilizing their uniquely patterned noticed fur. With this data, researchers on the Snow Leopard Belief can get a a lot better sense of leopard conduct, habitat, and motion. Moreover, figuring out particular person leopards helps researcher perceive inhabitants numbers, that are crucial for justifying Snow Leopard protections.
Conclusion
By means of this challenge we now have seen how new open supply computing instruments such because the Cognitive Companies on Spark, Deep Switch Studying, Distributed Mannequin Interpretability, and the TensorFlow Object Detection API can work collectively to drag an area particular object detector immediately from Bing. We now have additionally launched three new software program suites: The Cognitive Companies on Spark, Distributed Mannequin Interpretability, and Spark Serving, to make this evaluation easy and performant on Spark Clusters like Azure Databricks.
To recap, our evaluation consisted of the next essential steps:
- We gathered a classification dataset utilizing Bing on Spark.
- We skilled a deep classifier utilizing switch studying with CNTK on Spark.
- We Interpreted this deep classifier utilizing LIME on Spark to get areas of curiosity and bounding containers.
- We realized a deep object detector utilizing switch studying that recreates LIME’s outputs at a fraction of the price.
- We deployed the mannequin as a distributed net service with Spark Serving.
Here’s a graphical illustration of this evaluation:


Determine 13: Overview of the total structure described on this weblog publish.
Utilizing Microsoft ML for Apache Spark, customers can simply comply with in our footsteps and repeat this evaluation with their very own customized knowledge or Bing queries. We now have revealed this work within the open supply and invite others to attempt it for themselves, give suggestions, and assist us advance the sphere of distributed unsupervised studying.
We now have utilized this methodology to assist shield and monitor the endangered snow leopard inhabitants, however we made no assumptions all through this weblog on the kind of knowledge used. Inside a couple of hours we have been capable of modify this workflow to create a gasoline station hearth detection community for Shell Vitality with comparable success.
Mark Hamilton, for the MMLSpark Crew
Sources: