Multi -account support for Amazon Sagemaker Hyperpod’s tasks
GPUs are a precious source; They are both short in supply and much more expensive than traditional CPUs. They are also highly adaptable for many different use cases. Organizations that build or acquire generating GPUs use GPUs to execute simulations, execute conclusion (such as internal or external use), build work agent loads, and direct data scientists. Work loads range from single-GPU experiments with once rapidly led by scientists to continuous pre-coded continuous jogging. Many organizations need to share a centralized information infrastructure, with high GPU performance through different teams, business units or accounts within their organization. With this infrastructure, they can maximize the use of expensive accelerated calculation sources such as GPU, rather than having silent infrastructure that can be used. Organizations also use numerous AWS accounts for their users. Larger enterprises may want to share different business units, teams or environments (production, scene, development) on different AWS account. This provides more granular control and insulation between these different parts of the organization. It also makes it direct to trace and share the cloud costs for the relevant teams or business units for better financial supervision.
Specific reasons and configuration may vary depending on the size, structure and requirements of the enterprise. But in general, a multi -account strategy provides greater flexibility, security and management for large -scale placements. In this post, we discuss how an enterprise with multiple accounts can enter a common group Amazon Sagemaker Hyperpod for running their heterogeneous workloads. We use the governance of sagemaker hyperpod tasks to enable this feature.
Settlement
Sagemaker Hyperpod Task Governance determines resource division and provides grouping administrators the ability to set up policies to maximize the use of calculation in a group. Governance of tasks can be used to create distinct teams with their unique name space, to calculate quotes and borrowing boundaries. In a multi -account environment, you can limit which accounts have access to which the team’s calculation quota using role -based input control.
In this post, we describe the settings required to establish multi -account access to the Sagemaker Hyperpod group orchestrated by Amazon Elastic Kubbernetes (Amazon EG) service and how to use Sagemaker Hyperpod tasks to distribute accelerated accounts to multiple accounts.
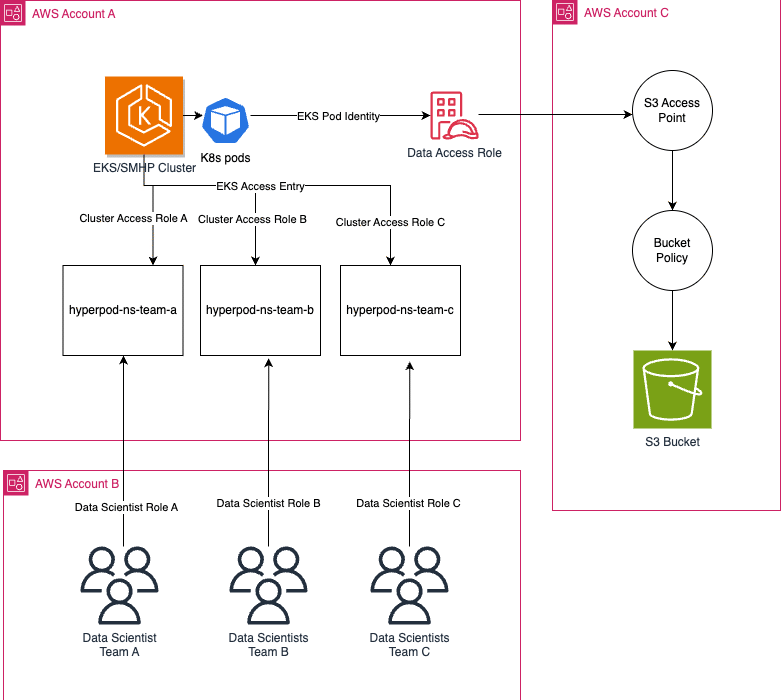
The following diagram illustrates the solution architecture.


In this architecture, an organization is sharing resources into several accounts. Calculate a Hyperpod Sagemaker cluster. Account B is where data scientists reside. Account C is where data is prepared and stored for the use of training. In the following sections, we demonstrate how to impose multi-account access so that data scientists in account B can train a model in account A, Sagemaker Hyperpod and Ex Cluster, using predefined data stored in account C. We break down this configuration into two sections: data calculation and inter-calculation.
Inter-calculation access to data scientists
When creating a calculating allocation with the governing sagemaker hyperpod tasks, your EG group creates a unique space of the team of the team for the team. For this way out, we create a role of AWS Identity and Access Management (IAM) for the team, called Group entry roleswhich are then access only in the name space generated by the team of the team in the common group. Role -based entry control is how we make sure that team data members A will not be able to present tasks on behalf of team B.
To access account group A of Account A as a user in account B, you will need to take a group entry role in account A. The role of entry into groups will only have the necessary permits for data scientists to access the EC group. For an example of IAM roles for data scientists using Hyperpod sagemaker, see IAM users for scientists.
Next, you will have to assume the role of group entry from a role in account B. The role of group entry into account A will have to have a belief policy for the role of data scientists in account B. The role of data scientists is the role in account B to be used to take on the role of accounting in account. In order to assume the role of access to the cluster in account A: Role: Role: A.
The following code is an example of the belief policy of the role of entering groups in order to allow the role of the data scientist to assume it:
The last step is to create an input input for the role of entry of the team group in the EC Group. This entry entry should also have an input policy, such as excedeitpolicy, which is located in the team’s names. This ensures that team A user in account B cannot start tasks outside their specified name space. You can also optionally set role -based access control; View Access Control -based Cubbernetes Control Control for more information.
For users in account B, you can repeat the same configuration for each team. You need to create a unique group access role for each team to approximate the role of entry for the team with their associated space space. To summarize, we use two different IAM roles:
- The Role of Data Scientist – Role in account B used to take on the role of group entry into account A. This role simply must be able to take on the role of entry into groups.
- The role of entry into groups – Role in the account used to provide access to the EC group. For example, see the role of IAM for Sagemaker Hyperpod.
Inter-calculation access to prepared data
In this section, we demonstrate how to create ex -pod identity and entry points S3 in order for pods to direct training tasks to the AK group of ACS Access to data stored in account C. EX POD allow you to draw a role of IAM in a name space account. If a pod uses the service account that has this association, then Amazon ex will set the environmental variables in the Pod containers.
Entry points S3 have been named the end points of the network that simplifies the input of the data for the shared data in the S3 buckets. They act as a way to give a good grain access to specific users or applications that enter a common database within a S3 bucket without asking those users or applications to have full access across the bucket. Permits at the entry point are granted through the policies of the entrance point S3. Point of entry point S3 is configured with a specific entry policy for a case of use or application. Since the hyperpod group in this blog post can be used by multiple teams, each team may have its own S3 entry point and the entry point policy.
Before following these steps, make sure you have an EX POD ID installer in your group.
- In Account A, create an IAM role containing S3 permit (such as
s3:ListBucketANDs3:GetObjectat the source of the entry point) and has a relationship of trust with the identity of the pod; This will be your role in data entry. Below is an example of a belief policy.
{
"Version": "2012-10-17",
"Statement": (
{
"Sid": "AllowEksAuthToAssumeRoleForPodIdentity",
"Effect": "Allow",
"Principal": {
"Service": "pods.eks.amazonaws.com"
},
"Action": (
"sts:AssumeRole",
"sts:TagSession"
)
}
)
}
- In account C, create a point of access S3 by following the steps here.
- Next, configure your entry point S3 to allow access to the role created in Step 1. This is a policy Example of entry point that accounts for a permit to enter the points in account C.
{
"Version": "2012-10-17",
"Statement": (
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam:::role/"
},
"Action": (
"s3:ListBucket",
"s3:GetObject"
),
"Resource": (
"arn:aws:s3:::accesspoint/",
"arn:aws:s3:::accesspoint//object/*"
)
}
)
}
- Make sure your S3 bucket policy is updated to allow the account an approach. This is a bucket policy S3 S3:
{
"Version": "2012-10-17",
"Statement": (
{
"Effect": "Allow",
"Principal": "*",
"Action": (
"s3:GetObject",
"s3:ListBucket"
),
"Resource": (
"arn:aws:s3:::",
"arn:aws:s3:::/*"
),
"Condition": {
"StringEquals": {
"s3:DataAccessPointAccount": ""
}
}
}
)
}
- In account A, create a POD identity association for your EX group using AWS CLI.
- Pods entering the buckets cross-account S3 will need the name of the service account referred to in their specification pod.
You can try the cross data input by rotating a test pod and execution on the pod to execute Amazon S3 commands:
This example shows the creation of a single role of entry into data for a single team. For numerous teams, use a serviceaccount specific for the name space with its own data entry role to help prevent overlap of resource access. You can also configure the Amazon S3 cross entry for an Amazon FSX for Luter File System in Account A, as described in USE Amazon FSX for Lusiness to divide Amazon S3 data through account. FSX for Luster and Amazon S3 will need to be in the same AWS region, and FSX for the Luter file system will need to be in the same availability zone as your Sagemaker Hyperpod group.
cONcluSiON
In this post, we have given guidance on how to create inter-calculation approaches for data scientists approaching a centralized group of Hyperpod Sagemaker orchestrated by Amazon ex. Moreover, we have covered how to provide Amazon S3 data access from one account to one group to another account. With the governing of the Sagemaker Hyperpod tasks, you can limit the entry and calculate allocation in specific teams. This architecture can be used on a scale by organizations that want to share a large accounting group through the accounts within their organization. To begin with the governing of the duties of Sagemaker Hyperpod, refer to the support of Amazon ex in the Amazon Sagemaker Hyperpod’s workshop and the documentation of the governing of Hyperpod Sagemaker Hyperpod.
About


Nisha Nadkarni is an old architect of specialized Genai solutions in AWS, where she guides companies through best practices when imposing large -scale training and conclusions in AWS. Prior to her current role, she spent several years in AWS focused on the help of developing Genai to develop models from the idea to production.