Studying Stairs Machine – Switch lesson for giant textual content corpus
This put up is the creator of Anusua Trived, a senior knowledge scientist in Microsoft.
This put up relies on the MRC weblog the place we mentioned how understanding of studying equipment (MRC) may help us “switch” any textual content. On this put up, we current the notion and the necessity to learn scale equipment, and to show switch to massive textual content corps.
presentation
Studying the equipment for answering the questions has turn out to be an vital check to guage how nicely pc methods perceive the human language. Additionally it is proving to be a vital expertise for functions similar to search engines like google and yahoo and dialog methods. The analysis group has just lately created a bunch of huge -scale knowledge on textual content sources, together with:
- Wikipedia (Wikireading, Staff, Wikihop).
- Useful information and articles for information (CNN/Every day Mail, Newsqa, Race).
- Fictitious tales (Mctest, CBT, Narratives).
- Common internet sources (Ms. Marco, Trivaqa, Searchqa).
These new knowledge, in flip, have impressed a fair wider group of recent questions of the questions.
In posting on the MRC weblog, we now have educated and examined varied MRC algorithms in these massive knowledge. We have been in a position to efficiently switch smaller textual content, besides utilizing these predefined MRC algorithms. Nevertheless, after we tried to create a QA system for the Gutenberg (English) ebook corpus utilizing these predetermined MRC fashions, algorithms failed. MRC often works within the textual content with the exception or paperwork, however fails for bigger textual content corpus. This leads us to a latest idea – studying equipment (MRS). Building machines that may make sense of studying equipment on scale can be of nice curiosity to enterprises.
Stair Equipment Studying (MRS)
As an alternative of specializing in solely smaller textual content fragments, Danqi Chen et al. It got here with an answer to a a lot greater drawback which is studying equipment on the dimensions. To fulfill the duty of studying Wikipedia to reply the questions with open area, they mixed a analysis element primarily based on the Hashing and TF-IDF that match a repeated nervous community sample with many layers educated to detect solutions in Wikipedia paragraphs.
MRC has to do with the reply to a query to a specific paragraph of the context. MRC algorithms often assume {that a} quick a part of the related textual content has already been recognized and given to the mannequin, which isn’t practical for constructing a system with open tombs.
In sharp distinction, the strategies that use info on paperwork ought to use the search as an integral a part of the answer.
The woman strikes a steadiness between two approaches. It’s centered on the simultaneous preservation of the problem of understanding equipment, which requires the deep understanding of the textual content, sustaining a practical analysis restriction on a big open supply.
Why is MRS vital to enterprises?
Enterprise chatbots has elevated quickly just lately. To additional advance these eventualities, analysis and trade are directed in the direction of the conversational approaches of it, particularly in circumstances of use similar to banking, insurance coverage and telecommunications, the place there are massive corpus of textbook data concerned.
One of many major challenges for the conversational one is to grasp advanced sentence sentences in the identical method as people. The problem turns into extra advanced when we now have to do that on massive volumes of textual content. MRS can handle each of those considerations the place it could actually reply goal questions from a big corpus with excessive accuracy. Such approaches can be utilized in actual -world functions as customer support.
On this put up we wish to recognize the MRS entry to resolve Computerized expertise that he cries by completely different massive corpus.
MRS coaching – DRQA mannequin
DQA is a system to learn the understanding utilized to the reply to open questions. The DQA is focused particularly within the activity of studying staircase equipment. On this setting, we’re asking for a solution to a query in a probably massive corpus of non -structured paperwork (which will not be redundant). Thus, the system should mix the challenges of acquiring paperwork (ie discovering related paperwork) with that of understanding the textual content (figuring out solutions from these paperwork).
We use the digital deep studying machine (DLVM) as the 2 libraries with two Nvidia Tesla P100 GPU, Cuda and Cudnn libraries. DLVM is a specifically configured variant of the digital knowledge science machine (DSVM) that makes the usage of VM -based VMs primarily based on coaching of deep studying fashions. It depends on Home windows 2016 and Ubuntu’s digital knowledge science. It shares the identical important VM photos – and thus the identical wealthy instruments – as DSVM, however is configured to make the educating simpler. All experiments have been executed in a Linux DLVM with two GPU Nvidia Tesla P100. We use Pytorch background to construct patterns. We PIP put in all of the addictions within the DLVM setting.
We fork Githubin of Fb analysis for our weblog work and we prepare the DRQA mannequin in crew knowledge. We use the pre-trained MRS mannequin for evaluating our massive Gutenberg corpus utilizing switch studying strategies.
Gutenberg Corps for Kids
We created a Gutenberg Corpus consisting of about 36,000 English books. We then created a subset of Gutenberg Corpus consisting of 528 kids’s books.
Pre-processing of Gutenberg Information for Youngster:
- Obtain filter books (eg kids, fairy tales, and so on.).
- Clear the downloaded books.
- Extract the textual content knowledge from the content material of the ebook.
Easy methods to create a customized corpus to work DRQA?
We observe the directions accessible right here to create a appropriate drawing of the Doc for Gutenberg Kids’s Books.
To execute the DRQA mannequin:
- Set a query at UI and click on on the search button.
- This calls the Demo server (the FASK server working within the Backend).
- Demo code begins the DRQA pipeline.
- DRQA pipeline elements are defined right here.
- The query is sacred.
- Based mostly on the tokenized query, the doc attraction makes use of the Hashing + TF-IDF BIGM to match many of the paperwork.
- We get the three finest matching paperwork.
- The doc reader (a multi -layer RNN) is then initiated to obtain the solutions from the doc.
- We use a predetermined mannequin in crew knowledge.
- We do studying of switch to Gutenberg’s knowledge for kids. You’ll be able to obtain the Gutenberg Kids’s E-book Corps Pre-processed for the DRSA mannequin right here.
- The mannequin’s embedded layer is initiated by Stanford Corenlp’s embedded vector.
- The mannequin returns the probably response house from every of the highest 3 paperwork.
- We will pace up the mannequin efficiency considerably by parallel knowledge conclusion, utilizing this mannequin on a number of GPUs.
The pipeline returns the probably checklist of solutions from the highest three extra matching paperwork.
We then execute the interactive pipeline utilizing this educated DRSA mannequin to strive the Gutenberg Kids’s E-book Corps.
For environmental configuration, please observe Readme.md In Gititub to obtain the code and set up the addictions. For all associated codes and particulars, please discuss with our Github hyperlink right here.
Girls utilizing DLVM
Please observe comparable steps listed on this pocket book to strive the DRSA mannequin in DLVM.
Classes from our appreciation work
On this put up, we now have investigated the efficiency of the MRS mannequin in our customized knowledge. We examined the efficiency of the switch studying entry to the creation of an QA system for about 528 kids’s books from Gutenberg Corpus Undertaking utilizing the predetermined DRSA mannequin. Our analysis outcomes are captured within the exhibitions beneath and the next rationalization. Notice that these outcomes are particular for our analysis situation – the outcomes will differ for different paperwork or eventualities.


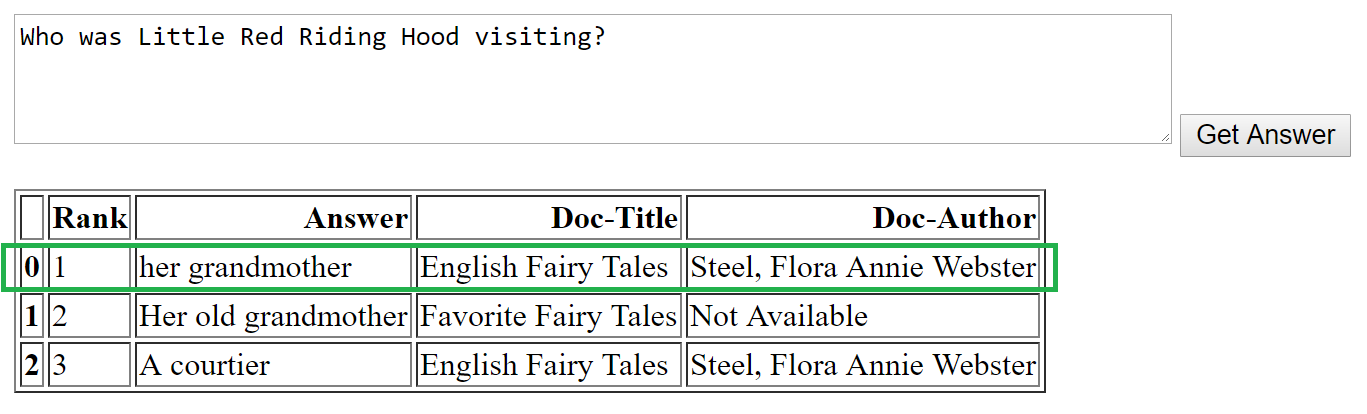
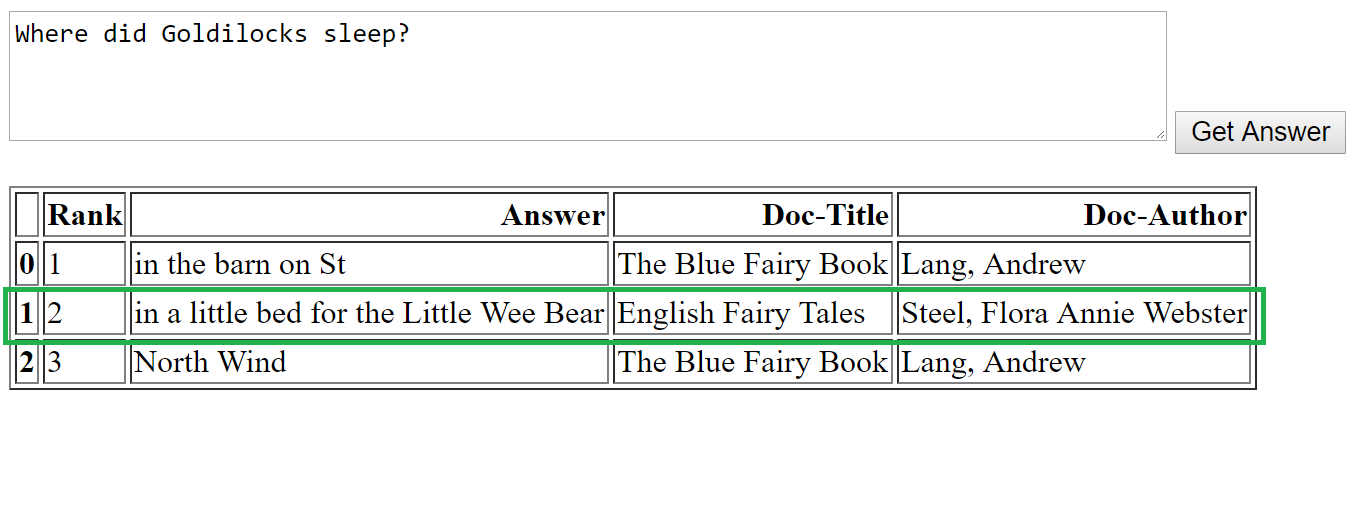






Within the examples above, we tried questions that start with what, how, the place, the place and why – and there is a vital facet for the woman value mentioning, particularly:
- The woman is finest fitted to “factoid” questions. Factoid questions relate to offering concise information. Eg “Who’s the Hogwarts Director?” or “what’s the inhabitants of Mars”. Thus, for what, who and the place the varieties of questions above, the woman works nicely.
- For non-fact questions (eg why), MRS doesn’t do an excellent job.
The inexperienced field represents the right reply for every query. As we see right here, for factoid questions, the solutions chosen by the MRS mannequin are in accordance with the right reply. Within the case of non-factor query “why”, nevertheless, the right reply is the third, and is the one one which is sensible.
On the whole, our analysis situation reveals that for giant corps of huge paperwork, the DRQA mannequin does an excellent job to reply factoid questions.
anus
@Anurive | E -mail Anusua to antriv@microsoft.com To questions associated to this put up.